 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASKCOS: an open source software suite for synthesis planning
Jan 03, 2025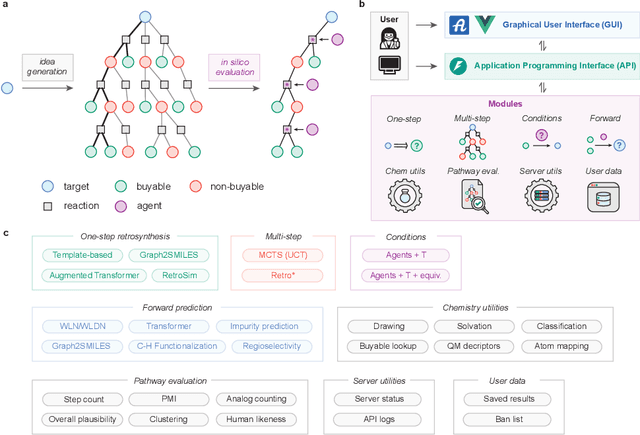



The advancement of machine learning and the availability of large-scale reaction datasets have accelerated the development of data-driven models for computer-aided synthesis planning (CASP) in the past decade. Here, we detail the newest version of ASKCOS, an open source software suite for synthesis planning that makes available several research advances in a freely available, practical tool. Four one-step retrosynthesis models form the basis of both interactive planning and automatic planning modes. Retrosynthetic planning is complemented by other modules for feasibility assessment and pathway evaluation, including reaction condition recommendation, reaction outcome prediction, and auxiliary capabilities such as solubility prediction and quantum mechanical descriptor prediction. ASKCOS has assisted hundreds of medicinal, synthetic, and process chemists in their day-to-day tasks, complementing expert decision making. It is our belief that CASP tools like ASKCOS are an important part of modern chemistry research, and that they offer ever-increasing utility and accessibility.
Probabilistic spatial clustering based on the Self Discipline Learning (SDL) model of autonomous learning
Jan 14, 2022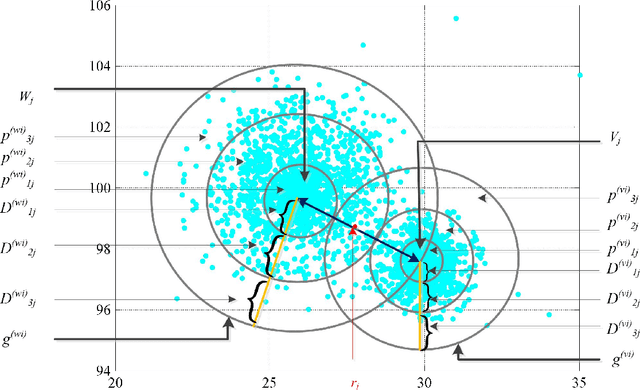
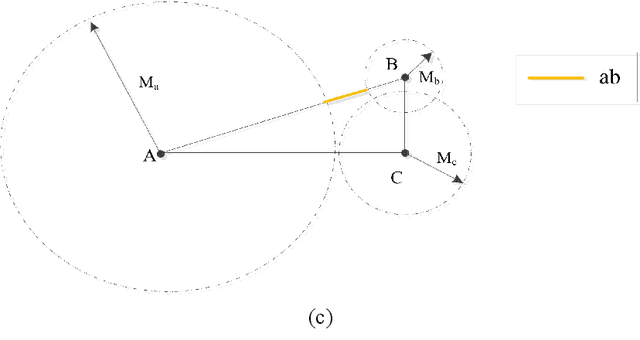
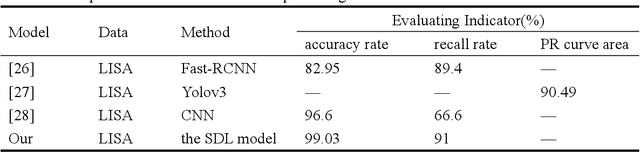
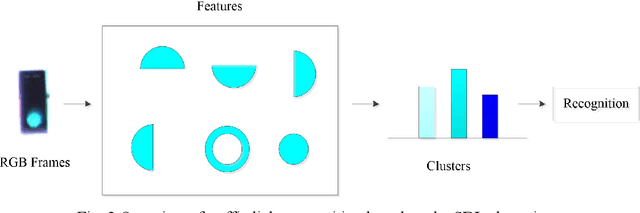
Unsupervised clustering algorithm can effectively reduce the dimension of high-dimensional unlabeled data, thus reducing the time and space complexity of data processing. However, the traditional clustering algorithm needs to set the upper bound of the number of categories in advance, and the deep learning clustering algorithm will fall into the problem of local optimum. In order to solve these problems, a probabilistic spatial clustering algorithm based on the Self Discipline Learning(SDL) model is proposed. The algorithm is based on the Gaussian probability distribution of the probability space distance between vectors, and uses the probability scale and maximum probability value of the probability space distance as the distance measurement judgment, and then determines the category of each sample according to the distribution characteristics of the data set itself. The algorithm is tested in Laboratory for Intelligent and Safe Automobiles(LISA) traffic light data set, the accuracy rate is 99.03%, the recall rate is 91%, and the effect is achieved.