 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic spatial clustering based on the Self Discipline Learning (SDL) model of autonomous learning
Paper and Code
Jan 14, 2022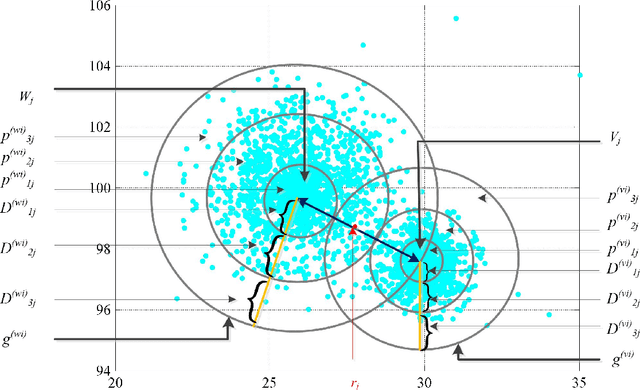
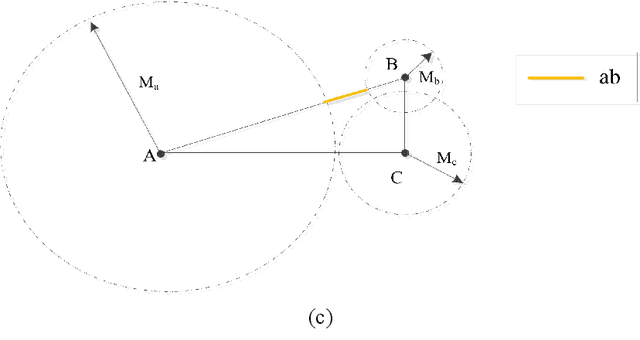
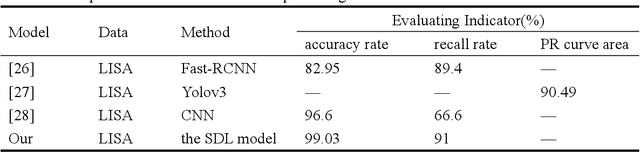
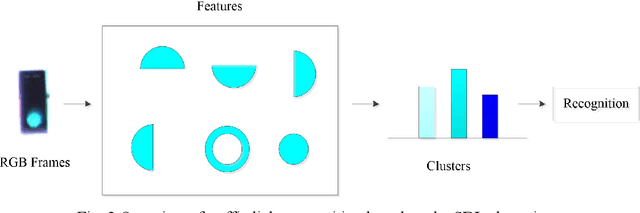
Unsupervised clustering algorithm can effectively reduce the dimension of high-dimensional unlabeled data, thus reducing the time and space complexity of data processing. However, the traditional clustering algorithm needs to set the upper bound of the number of categories in advance, and the deep learning clustering algorithm will fall into the problem of local optimum. In order to solve these problems, a probabilistic spatial clustering algorithm based on the Self Discipline Learning(SDL) model is proposed. The algorithm is based on the Gaussian probability distribution of the probability space distance between vectors, and uses the probability scale and maximum probability value of the probability space distance as the distance measurement judgment, and then determines the category of each sample according to the distribution characteristics of the data set itself. The algorithm is tested in Laboratory for Intelligent and Safe Automobiles(LISA) traffic light data set, the accuracy rate is 99.03%, the recall rate is 91%, and the effect is achieved.