 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Uncertainty Aware Movement Synchrony Estimation via Spatial-Temporal Graph Transformer
Aug 01, 2022


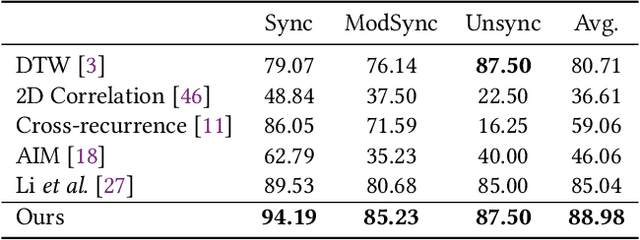
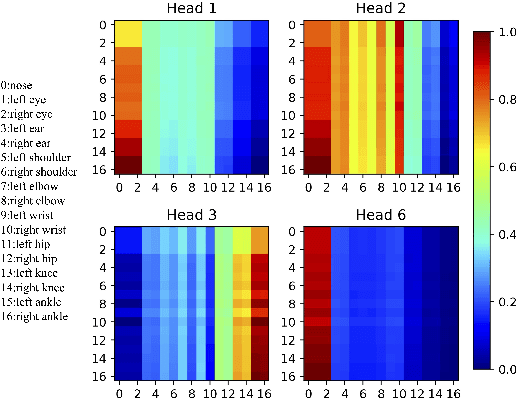
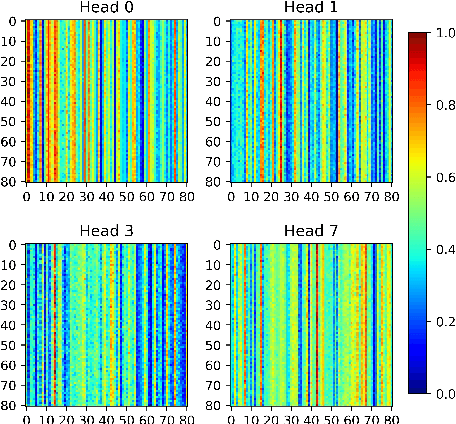
Movement synchrony reflects the coordination of body movements between interacting dyads. The estimation of movement synchrony has been automated by powerful deep learning models such as transformer networks. However, instead of designing a specialized network for movement synchrony estimation, previous transformer-based works broadly adopted architectures from other tasks such as human activity recognition. Therefore, this paper proposed a skeleton-based graph transformer for movement synchrony estimation. The proposed model applied ST-GCN, a spatial-temporal graph convolutional neural network for skeleton feature extraction, followed by a spatial transformer for spatial feature generation. The spatial transformer is guided by a uniquely designed joint position embedding shared between the same joints of interacting individuals. Besides, we incorporated a temporal similarity matrix in temporal attention computation considering the periodic intrinsic of body movements. In addition, the confidence score associated with each joint reflects the uncertainty of a pose, while previous works on movement synchrony estimation have not sufficiently emphasized this point. Since transformer networks demand a significant amount of data to train, we constructed a dataset for movement synchrony estimation using Human3.6M, a benchmark dataset for human activity recognition, and pretrained our model on it using contrastive learning. We further applied knowledge distillation to alleviate information loss introduced by pose detector failure in a privacy-preserving way. We compared our method with representative approaches on PT13, a dataset collected from autism therapy interventions. Our method achieved an overall accuracy of 88.98% and surpassed its counterparts by a wide margin while maintaining data privacy.
Dyadic Movement Synchrony Estimation Under Privacy-preserving Conditions
Aug 01, 2022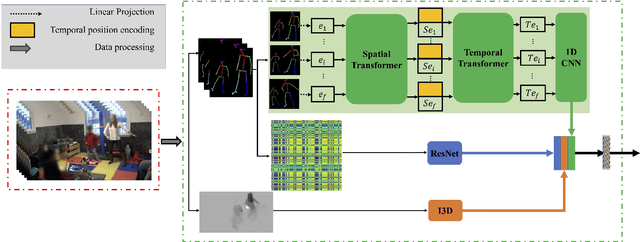

Movement synchrony refers to the dynamic temporal connection between the motions of interacting people. The applications of movement synchrony are wide and broad. For example, as a measure of coordination between teammates, synchrony scores are often reported in sports. The autism community also identifies movement synchrony as a key indicator of children's social and developmental achievements. In general, raw video recordings are often used for movement synchrony estimation, with the drawback that they may reveal people's identities. Furthermore, such privacy concern also hinders data sharing, one major roadblock to a fair comparison between different approaches in autism research. To address the issue, this paper proposes an ensemble method for movement synchrony estimation, one of the first deep-learning-based methods for automatic movement synchrony assessment under privacy-preserving conditions. Our method relies entirely on publicly shareable, identity-agnostic secondary data, such as skeleton data and optical flow. We validate our method on two datasets: (1) PT13 dataset collected from autism therapy interventions and (2) TASD-2 dataset collected from synchronized diving competitions. In this context, our method outperforms its counterpart approaches, both deep neural networks and alternatives.
A Two-stage Multi-modal Affect Analysis Framework for Children with Autism Spectrum Disorder
Jun 17, 2021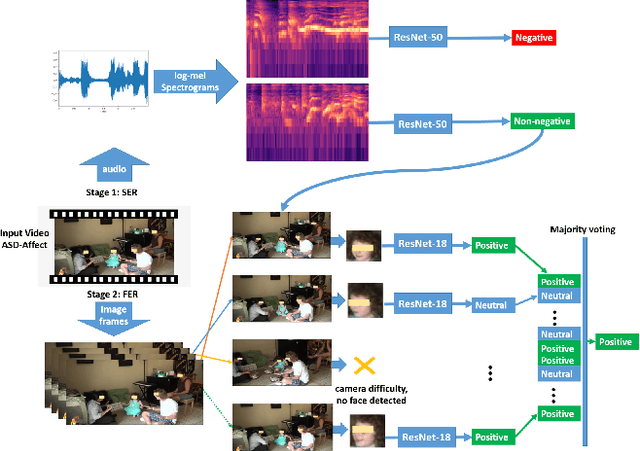

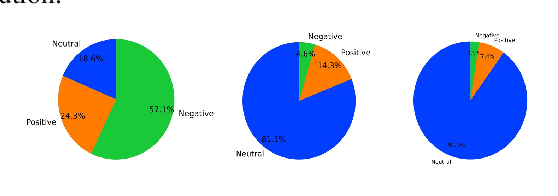
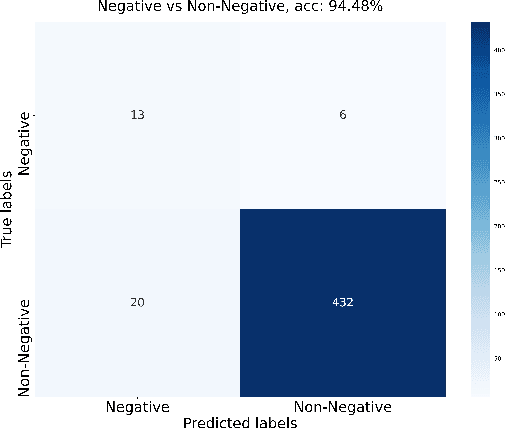
Autism spectrum disorder (ASD) is a developmental disorder that influences the communication and social behavior of a person in a way that those in the spectrum have difficulty in perceiving other people's facial expressions, as well as presenting and communicating emotions and affect via their own faces and bodies. Some efforts have been made to predict and improve children with ASD's affect states in play therapy, a common method to improve children's social skills via play and games. However, many previous works only used pre-trained models on benchmark emotion datasets and failed to consider the distinction in emotion between typically developing children and children with autism. In this paper, we present an open-source two-stage multi-modal approach leveraging acoustic and visual cues to predict three main affect states of children with ASD's affect states (positive, negative, and neutral) in real-world play therapy scenarios, and achieved an overall accuracy of 72:40%. This work presents a novel way to combine human expertise and machine intelligence for ASD affect recognition by proposing a two-stage schema.
* 8 pages including reference; 8 figures
Deep neural networks for collaborative learning analytics: Evaluating team collaborations using student gaze point prediction
Oct 16, 2020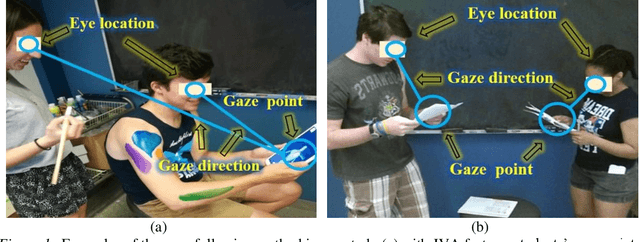
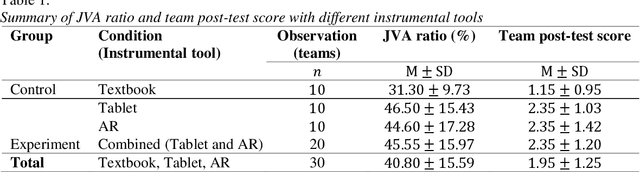
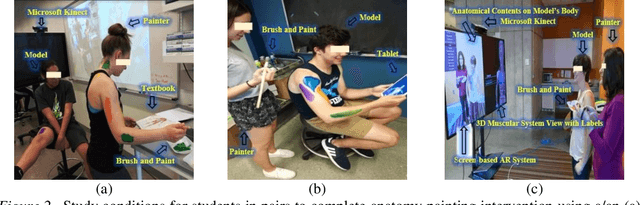
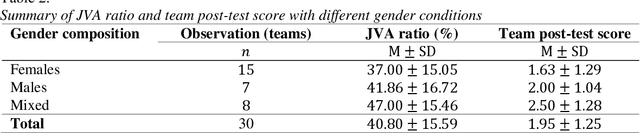
Automatic assessment and evaluation of team performance during collaborative tasks is key to the learning analytics and computer-supported cooperative work research. There is a growing interest in the use of gaze-oriented cues for evaluating the collaboration and cooperativeness of teams. However, collecting gaze data using eye-trackers is not always feasible due to time and cost constraints. In this paper, we introduce an automated team assessment tool based on gaze points and joint visual attention (JVA) information extracted by computer vision solutions. We then evaluate team collaborations in an undergraduate anatomy learning activity (N=60, 30 teams) as a test user-study. The results indicate that higher JVA was positively associated with student learning outcomes (r(30)=0.50,p<0.005). Moreover, teams who participated in two experimental groups, and used interactive 3-D anatomy models, had higher JVA (F(1,28)=6.65,p<0.05) and better knowledge retention (F(1,28) =7.56,p<0.05) than those in the control group. Also, no significant difference was observed based on JVA for different gender compositions of teams. The findings from this work offer implications in learning sciences and collaborative computing by providing a novel mutual attention-based measure to objectively evaluate team collaboration dynamics.
Augment Yourself: Mixed Reality Self-Augmentation Using Optical See-through Head-mounted Displays and Physical Mirrors
Jul 06, 2020
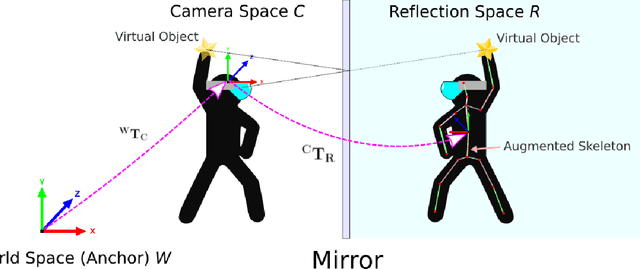
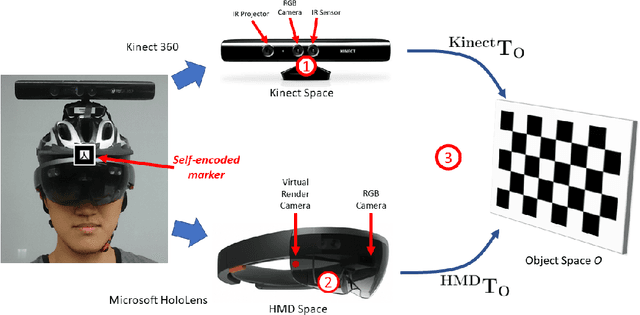
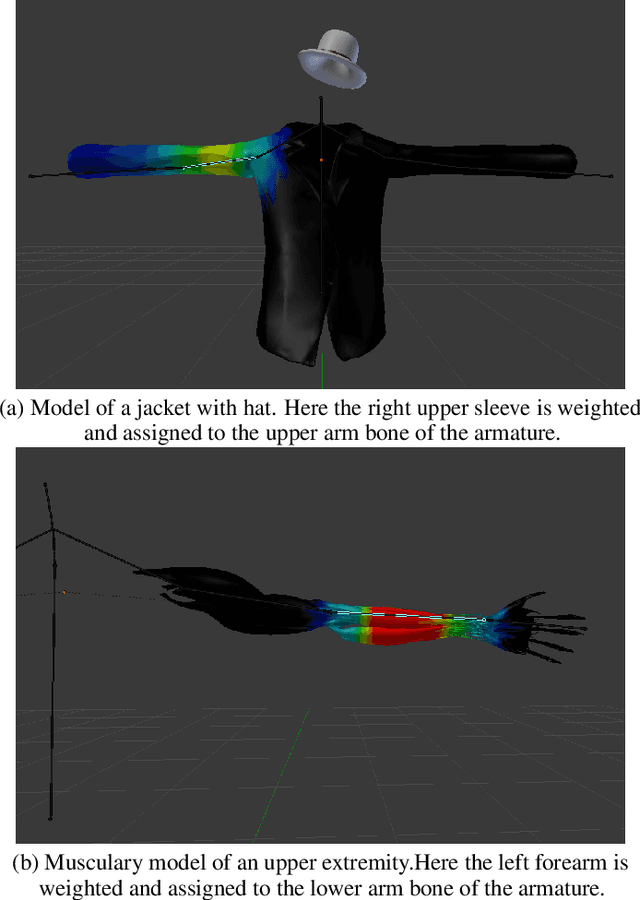
Optical see-though head-mounted displays (OST HMDs) are one of the key technologies for merging virtual objects and physical scenes to provide an immersive mixed reality (MR) environment to its user. A fundamental limitation of HMDs is, that the user itself cannot be augmented conveniently as, in casual posture, only the distal upper extremities are within the field of view of the HMD. Consequently, most MR applications that are centered around the user, such as virtual dressing rooms or learning of body movements, cannot be realized with HMDs. In this paper, we propose a novel concept and prototype system that combines OST HMDs and physical mirrors to enable self-augmentation and provide an immersive MR environment centered around the user. Our system, to the best of our knowledge the first of its kind, estimates the user's pose in the virtual image generated by the mirror using an RGBD camera attached to the HMD and anchors virtual objects to the reflection rather than the user directly. We evaluate our system quantitatively with respect to calibration accuracy and infrared signal degradation effects due to the mirror, and show its potential in applications where large mirrors are already an integral part of the facility. Particularly, we demonstrate its use for virtual fitting rooms, gaming applications, anatomy learning, and personal fitness. In contrast to competing devices such as LCD-equipped smart mirrors, the proposed system consists of only an HMD with RGBD camera and, thus, does not require a prepared environment making it very flexible and generic. In future work, we will aim to investigate how the system can be optimally used for physical rehabilitation and personal training as a promising application.
Collaboration Analysis Using Deep Learning
Apr 17, 2019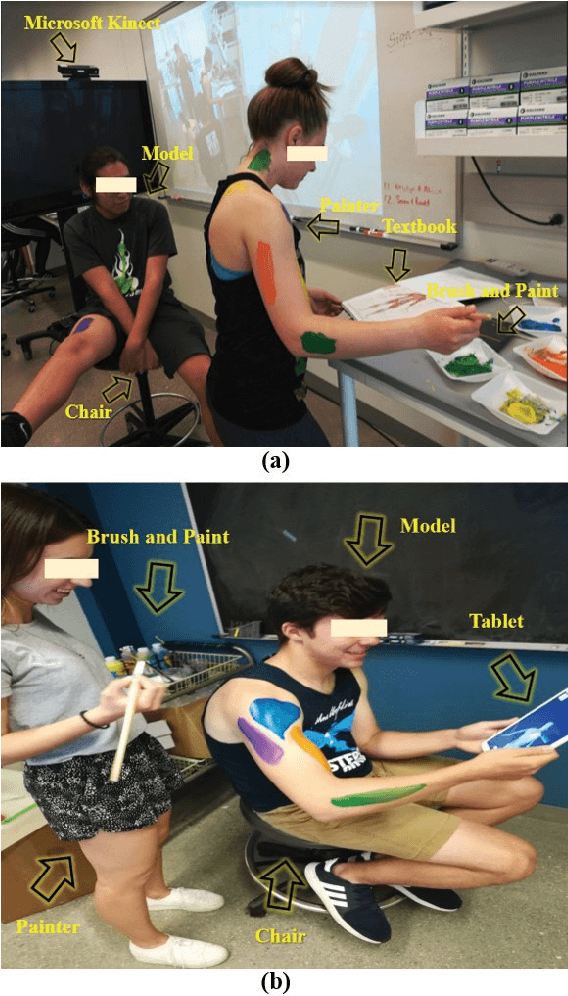


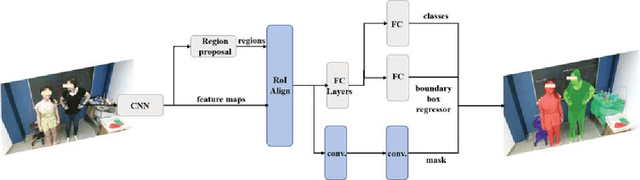
The analysis of the collaborative learning process is one of the growing fields of education research, which has many different analytic solutions. In this paper, we provided a new solution to improve automated collaborative learning analyses using deep neural networks. Instead of using self-reported questionnaires, which are subject to bias and noise, we automatically extract group-working information by object recognition results using Mask R-CNN method. This process is based on detecting the people and other objects from pictures and video clips of the collaborative learning process, then evaluate the mobile learning performance using the collaborative indicators. We tested our approach to automatically evaluate the group-work collaboration in a controlled study of thirty-three dyads while performing an anatomy body painting intervention. The results indicate that our approach recognizes the differences of collaborations among teams of treatment and control groups in the case study. This work introduces new methods for automated quality prediction of collaborations among human-human interactions using computer vision techniques.