 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying the Causes of Adversarial Examples
Paper and Code
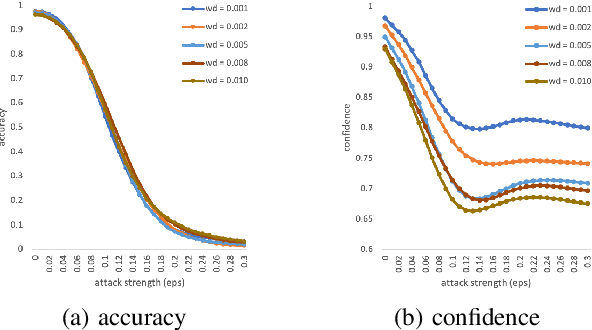
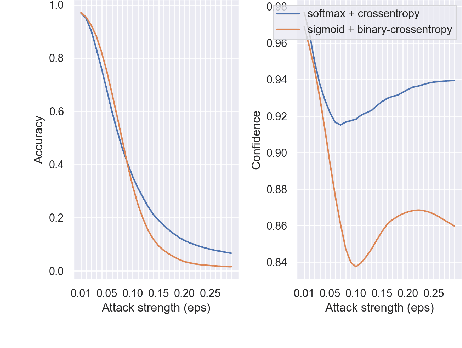
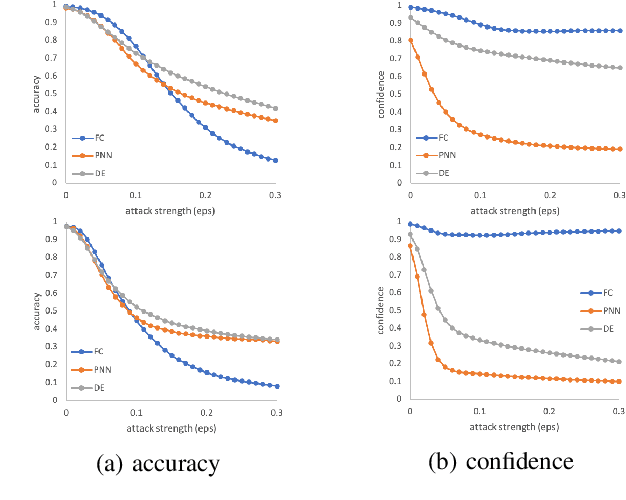
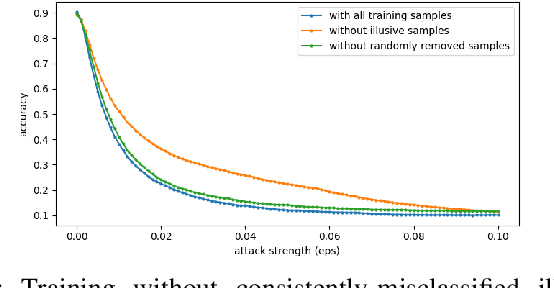
The robustness of neural networks is challenged by adversarial examples that contain almost imperceptible perturbations to inputs, which mislead a classifier to incorrect outputs in high confidence. Limited by the extreme difficulty in examining a high-dimensional image space thoroughly, research on explaining and justifying the causes of adversarial examples falls behind studies on attacks and defenses. In this paper, we present a collection of potential causes of adversarial examples and verify (or partially verify) them through carefully-designed controlled experiments. The major causes of adversarial examples include model linearity, one-sum constraint, and geometry of the categories. To control the effect of those causes, multiple techniques are applied such as $L_2$ normalization, replacement of loss functions, construction of reference datasets, and novel models using multi-layer perceptron probabilistic neural networks (MLP-PNN) and density estimation (DE). Our experiment results show that geometric factors tend to be more direct causes and statistical factors magnify the phenomenon, especially for assigning high prediction confidence. We believe this paper will inspire more studies to rigorously investigate the root causes of adversarial examples, which in turn provide useful guidance on designing more robust models.