 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonverbal Sound Detection for Disordered Speech
Feb 15, 2022
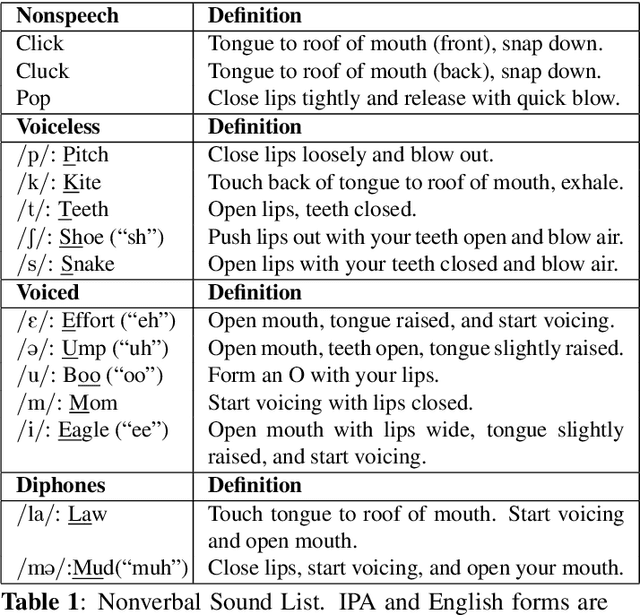


Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.
Quality-Efficiency Trade-offs in Machine Learning for Text Processing
Nov 07, 2017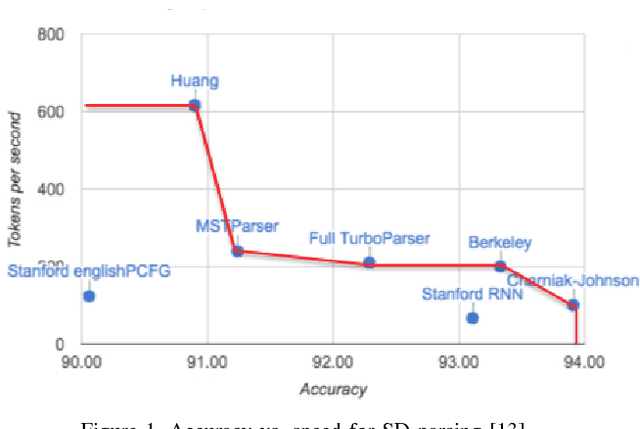
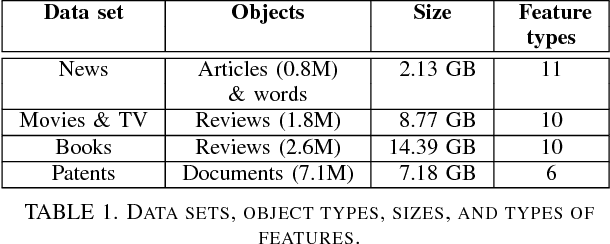
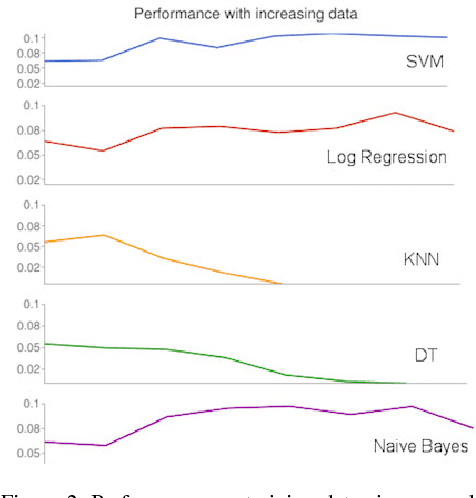
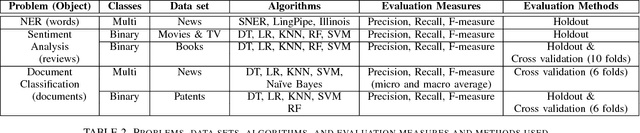
Data mining, machine learning, and natural language processing are powerful techniques that can be used together to extract information from large texts. Depending on the task or problem at hand, there are many different approaches that can be used. The methods available are continuously being optimized, but not all these methods have been tested and compared in a set of problems that can be solved using supervised machine learning algorithms. The question is what happens to the quality of the methods if we increase the training data size from, say, 100 MB to over 1 GB? Moreover, are quality gains worth it when the rate of data processing diminishes? Can we trade quality for time efficiency and recover the quality loss by just being able to process more data? We attempt to answer these questions in a general way for text processing tasks, considering the trade-offs involving training data size, learning time, and quality obtained. We propose a performance trade-off framework and apply it to three important text processing problems: Named Entity Recognition, Sentiment Analysis and Document Classification. These problems were also chosen because they have different levels of object granularity: words, paragraphs, and documents. For each problem, we selected several supervised machine learning algorithms and we evaluated the trade-offs of them on large publicly available data sets (news, reviews, patents). To explore these trade-offs, we use different data subsets of increasing size ranging from 50 MB to several GB. We also consider the impact of the data set and the evaluation technique. We find that the results do not change significantly and that most of the time the best algorithms is the fastest. However, we also show that the results for small data (say less than 100 MB) are different from the results for big data and in those cases the best algorithm is much harder to determine.