 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Imitation Learning from Video using a State Observer
Paper and Code
Feb 01, 2022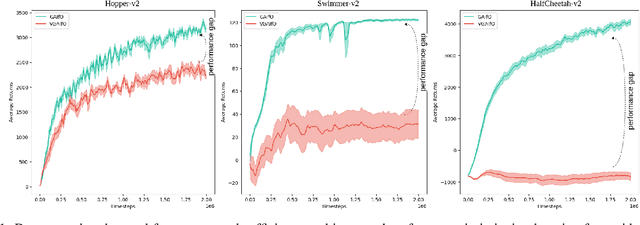
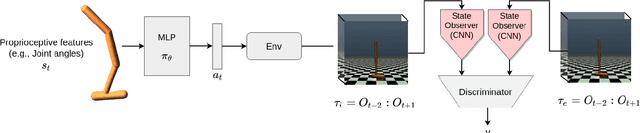
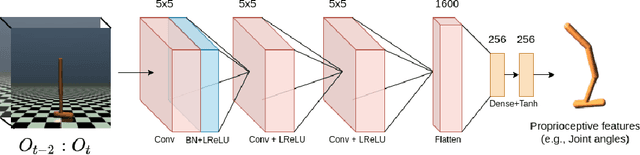
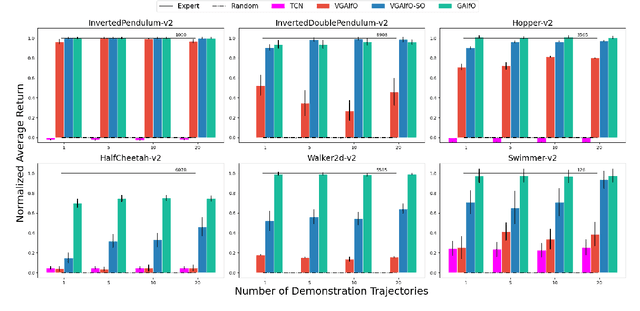
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.