 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Segmentation Using 3D Structure
Paper and Code
Nov 28, 2018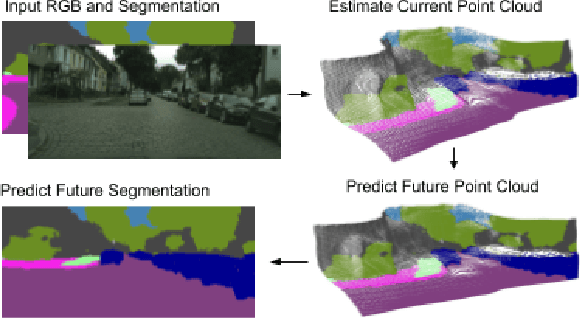

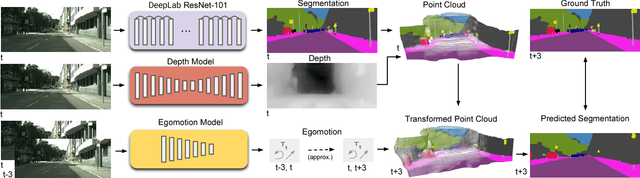

Predicting the future to anticipate the outcome of events and actions is a critical attribute of autonomous agents; particularly for agents which must rely heavily on real time visual data for decision making. Working towards this capability, we address the task of predicting future frame segmentation from a stream of monocular video by leveraging the 3D structure of the scene. Our framework is based on learnable sub-modules capable of predicting pixel-wise scene semantic labels, depth, and camera ego-motion of adjacent frames. We further propose a recurrent neural network based model capable of predicting future ego-motion trajectory as a function of a series of past ego-motion steps. Ultimately, we observe that leveraging 3D structure in the model facilitates successful prediction, achieving state of the art accuracy in future semantic segmentation.