 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Speed Cornering Control and Real-Vehicle Deployment for Autonomous Electric Vehicles
Nov 18, 2024Executing drift maneuvers during high-speed cornering presents significant challenges for autonomous vehicles, yet offers the potential to minimize turning time and enhance driving dynamics. While reinforcement learning (RL) has shown promising results in simulated environments, discrepancies between simulations and real-world conditions have limited its practical deployment. This study introduces an innovative control framework that integrates trajectory optimization with drift maneuvers, aiming to improve the algorithm's adaptability for real-vehicle implementation. We leveraged Bezier-based pre-trajectory optimization to enhance rewards and optimize the controller through Twin Delayed Deep Deterministic Policy Gradient (TD3) in a simulated environment. For real-world deployment, we implement a hybrid RL-MPC fusion mechanism, , where TD3-derived maneuvers serve as primary inputs for a Model Predictive Controller (MPC). This integration enables precise real-time tracking of the optimal trajectory, with MPC providing corrective inputs to bridge the gap between simulation and reality. The efficacy of this method is validated through real-vehicle tests on consumer-grade electric vehicles, focusing on drift U-turns and drift right-angle turns. The control outcomes of these real-vehicle tests are thoroughly documented in the paper, supported by supplementary video evidence (https://youtu.be/5wp67FcpfL8). Notably, this study is the first to deploy and apply an RL-based transient drift cornering algorithm on consumer-grade electric vehicles.
Model-based Reinforcement Learning with a Hamiltonian Canonical ODE Network
Nov 02, 2022Model-based reinforcement learning usually suffers from a high sample complexity in training the world model, especially for the environments with complex dynamics. To make the training for general physical environments more efficient, we introduce Hamiltonian canonical ordinary differential equations into the learning process, which inspires a novel model of neural ordinary differential auto-encoder (NODA). NODA can model the physical world by nature and is flexible to impose Hamiltonian mechanics (e.g., the dimension of the physical equations) which can further accelerate training of the environment models. It can consequentially empower an RL agent with the robust extrapolation using a small amount of samples as well as the guarantee on the physical plausibility. Theoretically, we prove that NODA has uniform bounds for multi-step transition errors and value errors under certain conditions. Extensive experiments show that NODA can learn the environment dynamics effectively with a high sample efficiency, making it possible to facilitate reinforcement learning agents at the early stage.
Object Gathering with a Tethered Robot Duo
Jan 12, 2022

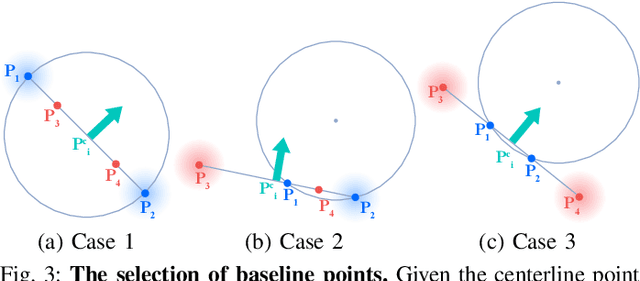
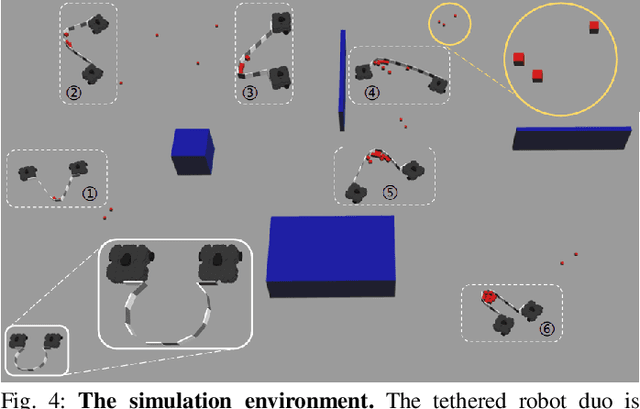
We devise a cooperative planning framework to generate optimal trajectories for a tethered robot duo, who is tasked to gather scattered objects spread in a large area using a flexible net. Specifically, the proposed planning framework first produces a set of dense waypoints for each robot, serving as the initialization for optimization. Next, we formulate an iterative optimization scheme to generate smooth and collision-free trajectories while ensuring cooperation within the robot duo to efficiently gather objects and properly avoid obstacles. We validate the generated trajectories in simulation and implement them in physical robots using Model Reference Adaptive Controller (MRAC) to handle unknown dynamics of carried payloads. In a series of studies, we find that: (i) a U-shape cost function is effective in planning cooperative robot duo, and (ii) the task efficiency is not always proportional to the tethered net's length. Given an environment configuration, our framework can gauge the optimal net length. To our best knowledge, ours is the first that provides such estimation for tethered robot duo.