 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan xLLMs Understand the Structure of Dialog? Exploring Multilingual Response Generation in Complex Scenarios
Jan 20, 2025Multilingual research has garnered increasing attention, especially in the domain of dialogue systems. The rapid advancements in large language models (LLMs) have fueled the demand for high-performing multilingual models. However, two major challenges persist: the scarcity of high-quality multilingual datasets and the limited complexity of existing datasets in capturing realistic dialogue scenarios. To address these gaps, we introduce XMP, a high-quality parallel Multilingual dataset sourced from Multi-party Podcast dialogues. Each sample in the dataset features at least three participants discussing a wide range of topics, including society, culture, politics, and entertainment.Through extensive experiments, we uncover significant limitations in previously recognized multilingual capabilities of LLMs when applied to such complex dialogue scenarios. For instance, the widely accepted multilingual complementary ability of LLMs is notably impacted. By conducting further experiments, we explore the mechanisms of LLMs in multilingual environments from multiple perspectives, shedding new light on their performance in real-world, diverse conversational contexts.
Advancing Multi-Party Dialogue Systems with Speaker-ware Contrastive Learning
Jan 20, 2025

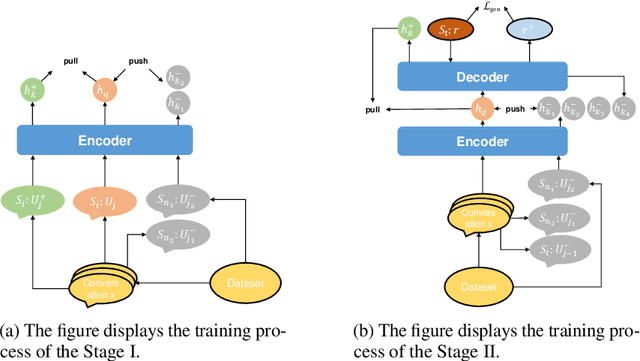

Dialogue response generation has made significant progress, but most research has focused on dyadic dialogue. In contrast, multi-party dialogues involve more participants, each potentially discussing different topics, making the task more complex. Current methods often rely on graph neural networks to model dialogue context, which helps capture the structural dynamics of multi-party conversations. However, these methods are heavily dependent on intricate graph structures and dataset annotations, and they often overlook the distinct speaking styles of participants. To address these challenges, we propose CMR, a Contrastive learning-based Multi-party dialogue Response generation model. CMR uses self-supervised contrastive learning to better distinguish "who says what." Additionally, by comparing speakers within the same conversation, the model captures differences in speaking styles and thematic transitions. To the best of our knowledge, this is the first approach to apply contrastive learning in multi-party dialogue generation. Experimental results show that CMR significantly outperforms state-of-the-art models in multi-party dialogue response tasks.
UniRQR: A Unified Model for Retrieval Decision, Query, and Response Generation in Internet-Based Knowledge Dialogue Systems
Jan 11, 2024


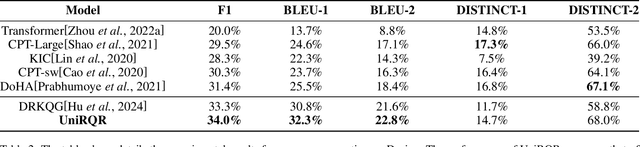
Knowledge-based dialogue systems with internet retrieval have recently attracted considerable attention from researchers. The dialogue systems overcome a major limitation of traditional knowledge dialogue systems, where the timeliness of knowledge cannot be assured, hence providing greater practical application value. Knowledge-based dialogue systems with internet retrieval can be typically segmented into three tasks: Retrieval Decision, Query Generation, and Response Generation. However, many of studies assumed that all conversations require external knowledge to continue, neglecting the critical step of determining when retrieval is necessary. This assumption often leads to an over-dependence on external knowledge, even when it may not be required. Our work addresses this oversight by employing a single unified model facilitated by prompt and multi-task learning approaches. This model not only decides whether retrieval is necessary but also generates retrieval queries and responses. By integrating these functions, our system leverages the full potential of pre-trained models and reduces the complexity and costs associated with deploying multiple models. We conducted extensive experiments to investigate the mutual enhancement among the three tasks in our system. What is more, the experiment results on the Wizint and Dusinc datasets not only demonstrate that our unified model surpasses the baseline performance for individual tasks, but also reveal that it achieves comparable results when contrasted with SOTA systems that deploy separate, specialized models for each task.
Coordination for Connected and Automated Vehicles at Non-signalized Intersections: A Value Decomposition-based Multiagent Deep Reinforcement Learning Approach
Nov 16, 2022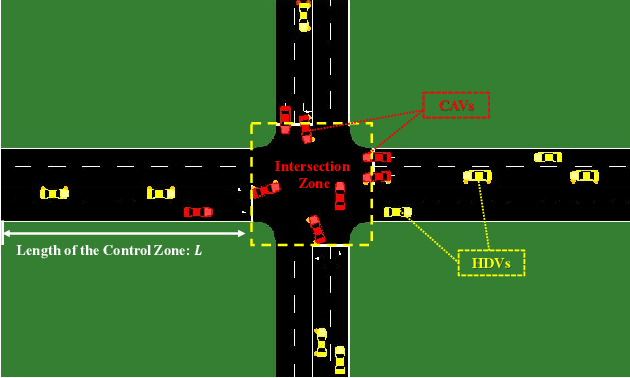
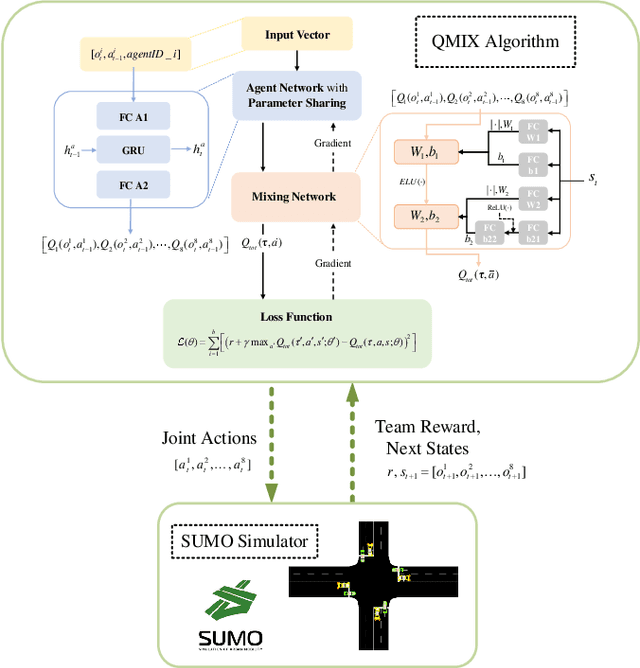
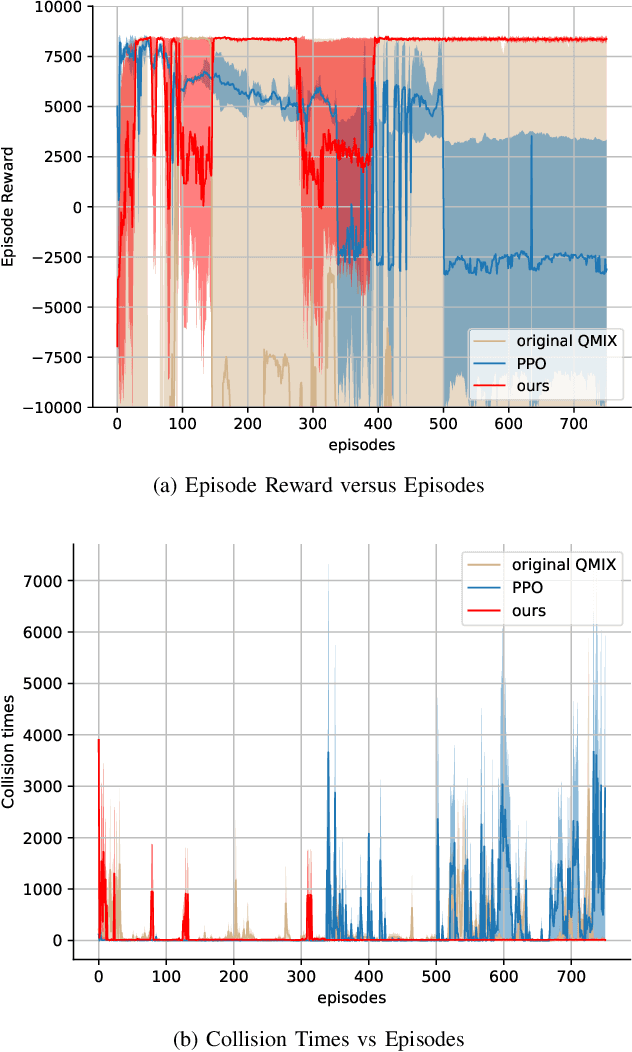
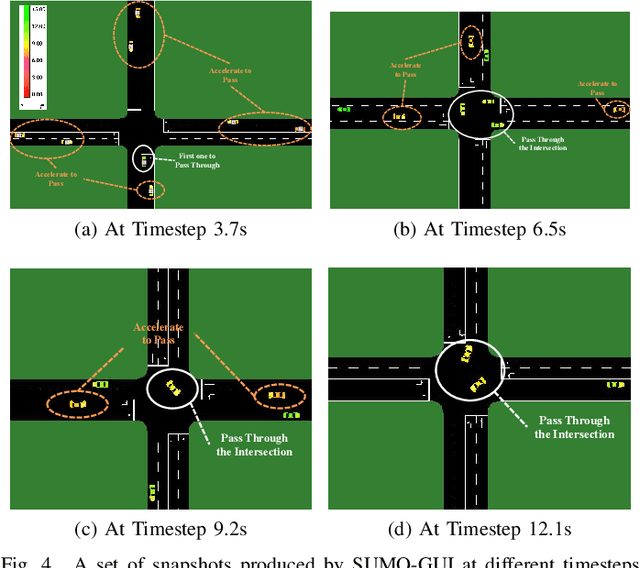
The recent proliferation of the research on multi-agent deep reinforcement learning (MDRL) offers an encouraging way to coordinate multiple connected and automated vehicles (CAVs) to pass the intersection. In this paper, we apply a value decomposition-based MDRL approach (QMIX) to control various CAVs in mixed-autonomy traffic of different densities to efficiently and safely pass the non-signalized intersection with fairish fuel consumption. Implementation tricks including network-level improvements, Q value update by TD ($\lambda$), and reward clipping operation are added to the pure QMIX framework, which is expected to improve the convergence speed and the asymptotic performance of the original version. The efficacy of our approach is demonstrated by several evaluation metrics: average speed, the number of collisions, and average fuel consumption per episode. The experimental results show that our approach's convergence speed and asymptotic performance can exceed that of the original QMIX and the proximal policy optimization (PPO), a state-of-the-art reinforcement learning baseline applied to the non-signalized intersection. Moreover, CAVs under the lower traffic flow controlled by our method can improve their average speed without collisions and consume the least fuel. The training is additionally conducted under the doubled traffic density, where the learning reward converges. Consequently, the model with maximal reward and minimum crashes can still guarantee low fuel consumption, but slightly reduce the efficiency of vehicles and induce more collisions than the lower-traffic counterpart, implying the difficulty of generalizing RL policy to more advanced scenarios.
Dynamically Retrieving Knowledge via Query Generation for informative dialogue response
Jul 30, 2022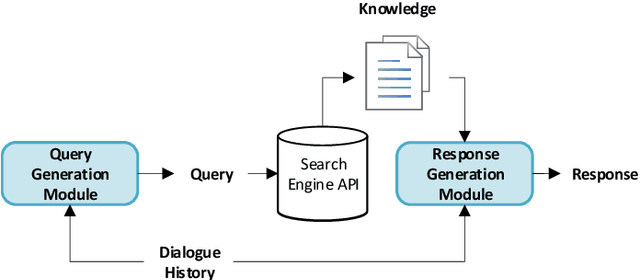
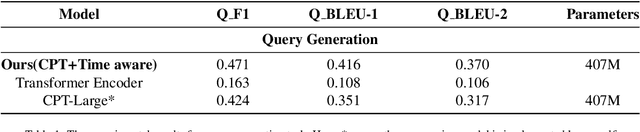
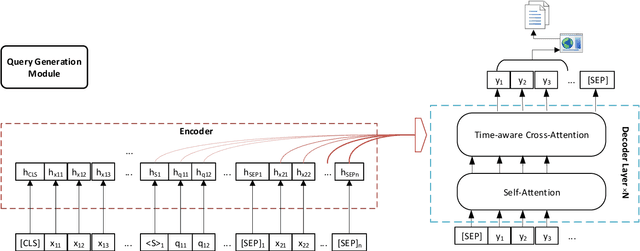
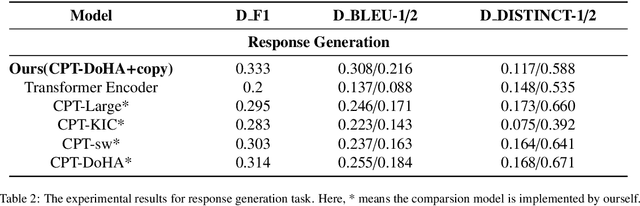
Knowledge-driven dialogue generation has recently made remarkable breakthroughs. Compared with general dialogue systems, superior knowledge-driven dialogue systems can generate more informative and knowledgeable responses with pre-provided knowledge. However, in practical applications, the dialogue system cannot be provided with corresponding knowledge in advance. In order to solve the problem, we design a knowledge-driven dialogue system named DRKQG (\emph{Dynamically Retrieving Knowledge via Query Generation for informative dialogue response}). Specifically, the system can be divided into two modules: query generation module and dialogue generation module. First, a time-aware mechanism is utilized to capture context information and a query can be generated for retrieving knowledge. Then, we integrate copy Mechanism and Transformers, which allows the response generation module produces responses derived from the context and retrieved knowledge. Experimental results at LIC2022, Language and Intelligence Technology Competition, show that our module outperforms the baseline model by a large margin on automatic evaluation metrics, while human evaluation by Baidu Linguistics team shows that our system achieves impressive results in Factually Correct and Knowledgeable.