 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXPO: Preference Optimization for Chest X-ray VLMs with Counterfactual Rationale
Jul 09, 2025Vision-language models (VLMs) are prone to hallucinations that critically compromise reliability in medical applications. While preference optimization can mitigate these hallucinations through clinical feedback, its implementation faces challenges such as clinically irrelevant training samples, imbalanced data distributions, and prohibitive expert annotation costs. To address these challenges, we introduce CheXPO, a Chest X-ray Preference Optimization strategy that combines confidence-similarity joint mining with counterfactual rationale. Our approach begins by synthesizing a unified, fine-grained multi-task chest X-ray visual instruction dataset across different question types for supervised fine-tuning (SFT). We then identify hard examples through token-level confidence analysis of SFT failures and use similarity-based retrieval to expand hard examples for balancing preference sample distributions, while synthetic counterfactual rationales provide fine-grained clinical preferences, eliminating the need for additional expert input. Experiments show that CheXPO achieves 8.93% relative performance gain using only 5% of SFT samples, reaching state-of-the-art performance across diverse clinical tasks and providing a scalable, interpretable solution for real-world radiology applications.
Can xLLMs Understand the Structure of Dialog? Exploring Multilingual Response Generation in Complex Scenarios
Jan 20, 2025Multilingual research has garnered increasing attention, especially in the domain of dialogue systems. The rapid advancements in large language models (LLMs) have fueled the demand for high-performing multilingual models. However, two major challenges persist: the scarcity of high-quality multilingual datasets and the limited complexity of existing datasets in capturing realistic dialogue scenarios. To address these gaps, we introduce XMP, a high-quality parallel Multilingual dataset sourced from Multi-party Podcast dialogues. Each sample in the dataset features at least three participants discussing a wide range of topics, including society, culture, politics, and entertainment.Through extensive experiments, we uncover significant limitations in previously recognized multilingual capabilities of LLMs when applied to such complex dialogue scenarios. For instance, the widely accepted multilingual complementary ability of LLMs is notably impacted. By conducting further experiments, we explore the mechanisms of LLMs in multilingual environments from multiple perspectives, shedding new light on their performance in real-world, diverse conversational contexts.
Advancing Multi-Party Dialogue Systems with Speaker-ware Contrastive Learning
Jan 20, 2025

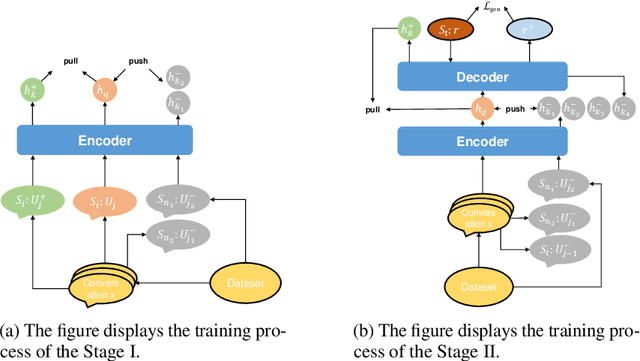

Dialogue response generation has made significant progress, but most research has focused on dyadic dialogue. In contrast, multi-party dialogues involve more participants, each potentially discussing different topics, making the task more complex. Current methods often rely on graph neural networks to model dialogue context, which helps capture the structural dynamics of multi-party conversations. However, these methods are heavily dependent on intricate graph structures and dataset annotations, and they often overlook the distinct speaking styles of participants. To address these challenges, we propose CMR, a Contrastive learning-based Multi-party dialogue Response generation model. CMR uses self-supervised contrastive learning to better distinguish "who says what." Additionally, by comparing speakers within the same conversation, the model captures differences in speaking styles and thematic transitions. To the best of our knowledge, this is the first approach to apply contrastive learning in multi-party dialogue generation. Experimental results show that CMR significantly outperforms state-of-the-art models in multi-party dialogue response tasks.
UniRQR: A Unified Model for Retrieval Decision, Query, and Response Generation in Internet-Based Knowledge Dialogue Systems
Jan 11, 2024


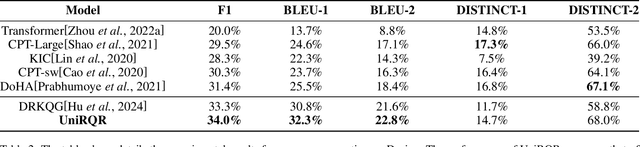
Knowledge-based dialogue systems with internet retrieval have recently attracted considerable attention from researchers. The dialogue systems overcome a major limitation of traditional knowledge dialogue systems, where the timeliness of knowledge cannot be assured, hence providing greater practical application value. Knowledge-based dialogue systems with internet retrieval can be typically segmented into three tasks: Retrieval Decision, Query Generation, and Response Generation. However, many of studies assumed that all conversations require external knowledge to continue, neglecting the critical step of determining when retrieval is necessary. This assumption often leads to an over-dependence on external knowledge, even when it may not be required. Our work addresses this oversight by employing a single unified model facilitated by prompt and multi-task learning approaches. This model not only decides whether retrieval is necessary but also generates retrieval queries and responses. By integrating these functions, our system leverages the full potential of pre-trained models and reduces the complexity and costs associated with deploying multiple models. We conducted extensive experiments to investigate the mutual enhancement among the three tasks in our system. What is more, the experiment results on the Wizint and Dusinc datasets not only demonstrate that our unified model surpasses the baseline performance for individual tasks, but also reveal that it achieves comparable results when contrasted with SOTA systems that deploy separate, specialized models for each task.