 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Data Augmentation Approaches to End-to-End Task-Oriented Dialogue
Paper and Code
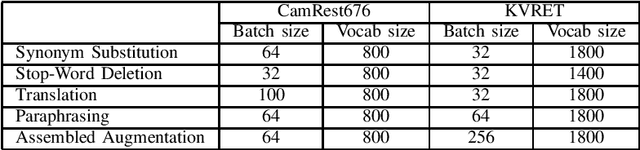


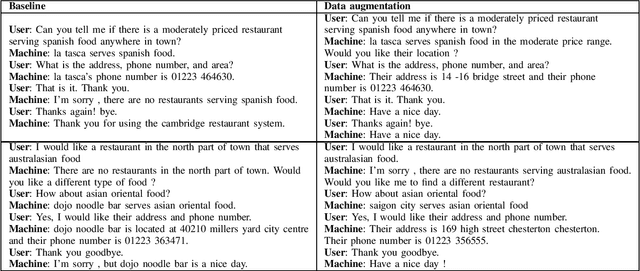
The training of task-oriented dialogue systems is often confronted with the lack of annotated data. In contrast to previous work which augments training data through expensive crowd-sourcing efforts, we propose four different automatic approaches to data augmentation at both the word and sentence level for end-to-end task-oriented dialogue and conduct an empirical study on their impact. Experimental results on the CamRest676 and KVRET datasets demonstrate that each of the four data augmentation approaches is able to obtain a significant improvement over a strong baseline in terms of Success F1 score and that the ensemble of the four approaches achieves the state-of-the-art results in the two datasets. In-depth analyses further confirm that our methods adequately increase the diversity of user utterances, which enables the end-to-end model to learn features robustly.