 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Changes Make Big Differences: Improving Multi-turn Response Selection in Dialogue Systems via Fine-Grained Contrastive Learning
Paper and Code
Nov 25, 2021
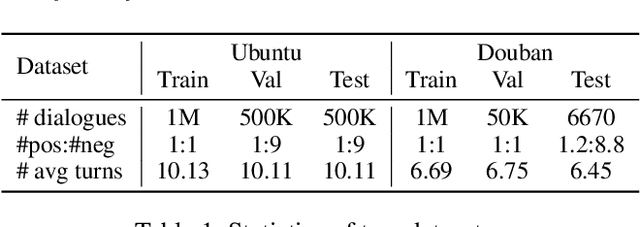
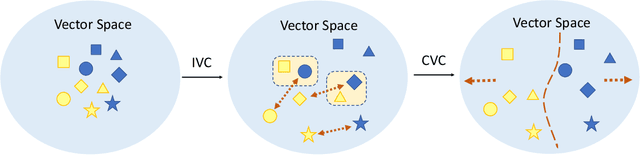
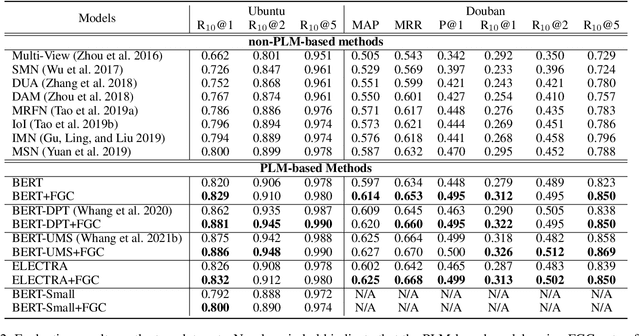
Retrieve-based dialogue response selection aims to find a proper response from a candidate set given a multi-turn context. Pre-trained language models (PLMs) based methods have yielded significant improvements on this task. The sequence representation plays a key role in the learning of matching degree between the dialogue context and the response. However, we observe that different context-response pairs sharing the same context always have a greater similarity in the sequence representations calculated by PLMs, which makes it hard to distinguish positive responses from negative ones. Motivated by this, we propose a novel \textbf{F}ine-\textbf{G}rained \textbf{C}ontrastive (FGC) learning method for the response selection task based on PLMs. This FGC learning strategy helps PLMs to generate more distinguishable matching representations of each dialogue at fine grains, and further make better predictions on choosing positive responses. Empirical studies on two benchmark datasets demonstrate that the proposed FGC learning method can generally and significantly improve the model performance of existing PLM-based matching models.