 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTegTok: Augmenting Text Generation via Task-specific and Open-world Knowledge
Paper and Code
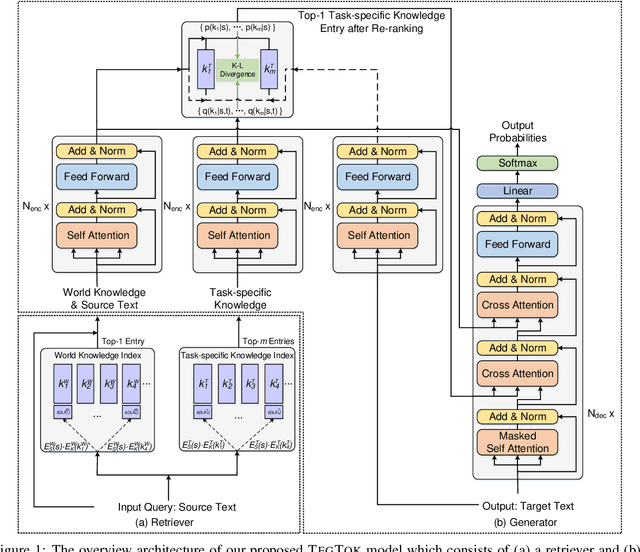
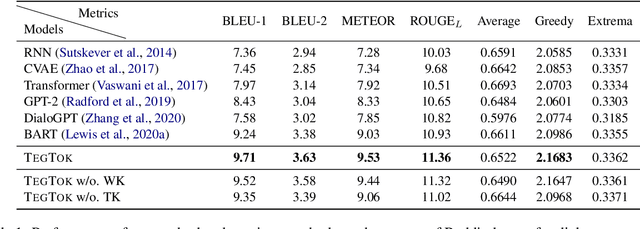
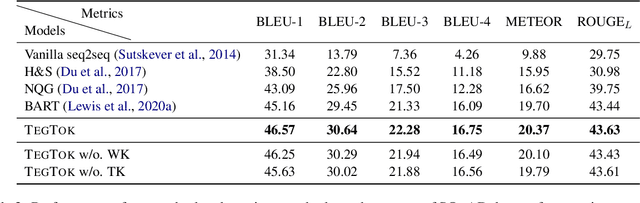
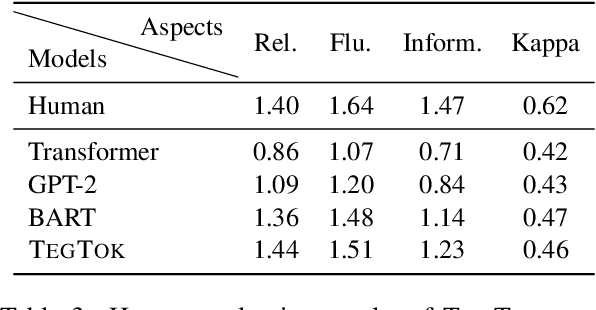
Generating natural and informative texts has been a long-standing problem in NLP. Much effort has been dedicated into incorporating pre-trained language models (PLMs) with various open-world knowledge, such as knowledge graphs or wiki pages. However, their ability to access and manipulate the task-specific knowledge is still limited on downstream tasks, as this type of knowledge is usually not well covered in PLMs and is hard to acquire. To address the problem, we propose augmenting TExt Generation via Task-specific and Open-world Knowledge (TegTok) in a unified framework. Our model selects knowledge entries from two types of knowledge sources through dense retrieval and then injects them into the input encoding and output decoding stages respectively on the basis of PLMs. With the help of these two types of knowledge, our model can learn what and how to generate. Experiments on two text generation tasks of dialogue generation and question generation, and on two datasets show that our method achieves better performance than various baseline models.