 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegMo: Segment-aligned Text to 3D Human Motion Generation
Dec 24, 2025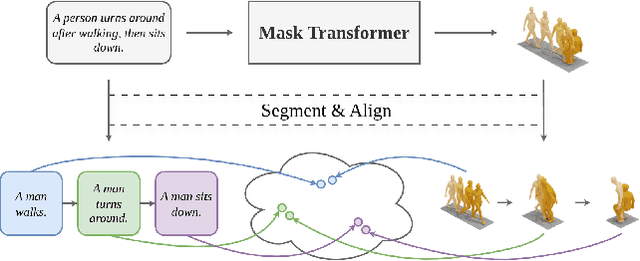
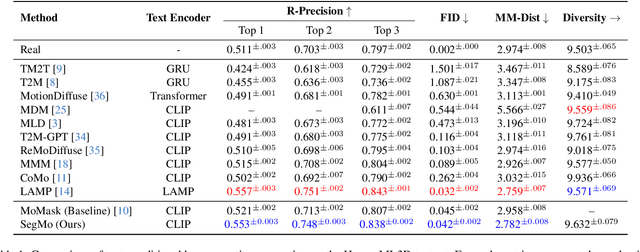
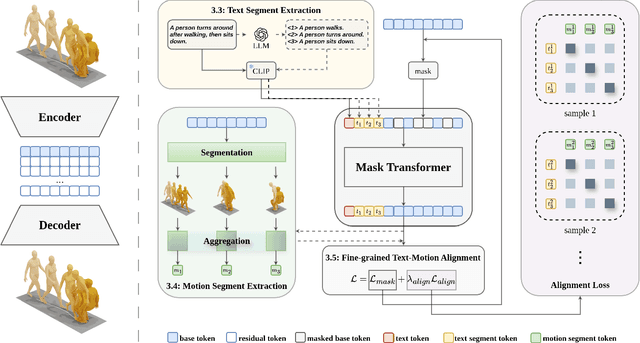
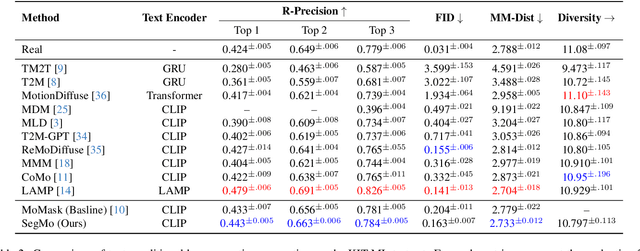
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
Jun 09, 2024This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
Reconstructing 3D Human Pose from RGB-D Data with Occlusions
Oct 15, 2023We propose a new method to reconstruct the 3D human body from RGB-D images with occlusions. The foremost challenge is the incompleteness of the RGB-D data due to occlusions between the body and the environment, leading to implausible reconstructions that suffer from severe human-scene penetration. To reconstruct a semantically and physically plausible human body, we propose to reduce the solution space based on scene information and prior knowledge. Our key idea is to constrain the solution space of the human body by considering the occluded body parts and visible body parts separately: modeling all plausible poses where the occluded body parts do not penetrate the scene, and constraining the visible body parts using depth data. Specifically, the first component is realized by a neural network that estimates the candidate region named the "free zone", a region carved out of the open space within which it is safe to search for poses of the invisible body parts without concern for penetration. The second component constrains the visible body parts using the "truncated shadow volume" of the scanned body point cloud. Furthermore, we propose to use a volume matching strategy, which yields better performance than surface matching, to match the human body with the confined region. We conducted experiments on the PROX dataset, and the results demonstrate that our method produces more accurate and plausible results compared with other methods.