 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learned Index for Exact Similarity Search in Metric Spaces
Paper and Code

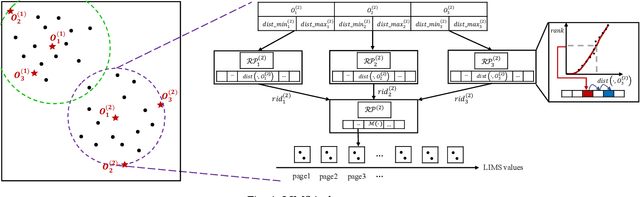


Indexing is an effective way to support efficient query processing in large databases. Recently the concept of learned index has been explored actively to replace or supplement traditional index structures with machine learning models to reduce storage and search costs. However, accurate and efficient similarity query processing in high-dimensional metric spaces remains to be an open challenge. In this paper, a novel indexing approach called LIMS is proposed to use data clustering and pivot-based data transformation techniques to build learned indexes for efficient similarity query processing in metric spaces. The underlying data is partitioned into clusters such that each cluster follows a relatively uniform data distribution. Data redistribution is achieved by utilizing a small number of pivots for each cluster. Similar data are mapped into compact regions and the mapped values are totally ordinal. Machine learning models are developed to approximate the position of each data record on the disk. Efficient algorithms are designed for processing range queries and nearest neighbor queries based on LIMS, and for index maintenance with dynamic updates. Extensive experiments on real-world and synthetic datasets demonstrate the superiority of LIMS compared with traditional indexes and state-of-the-art learned indexes.