Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Transformer-based Speech Recognition Using Unsupervised Pre-training
Paper and Code
Oct 31, 2019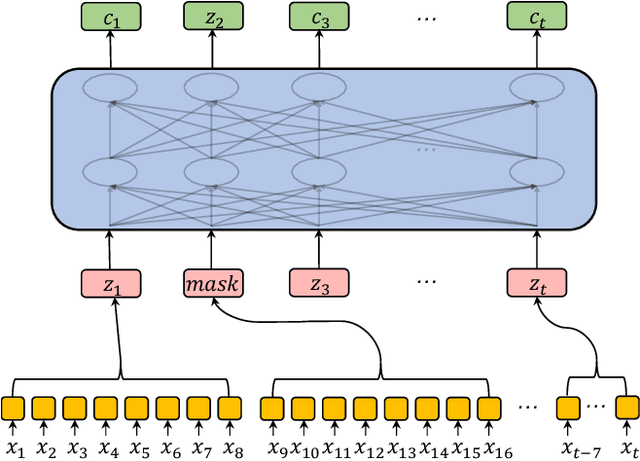
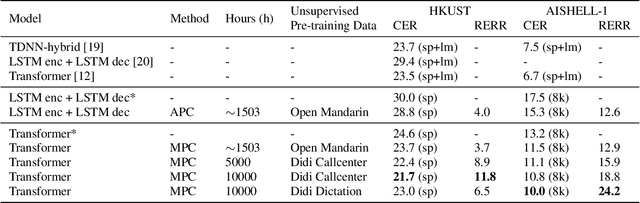
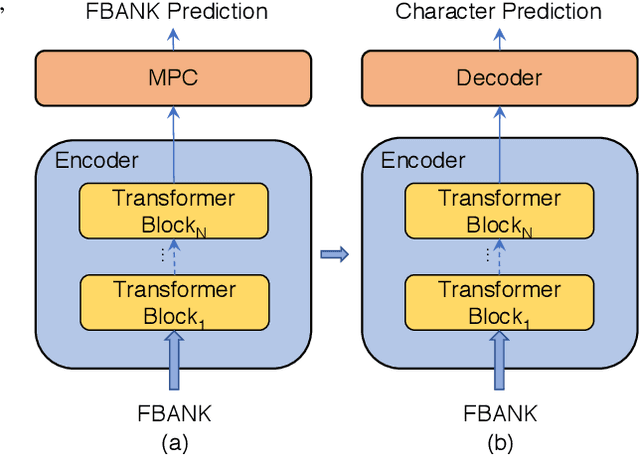
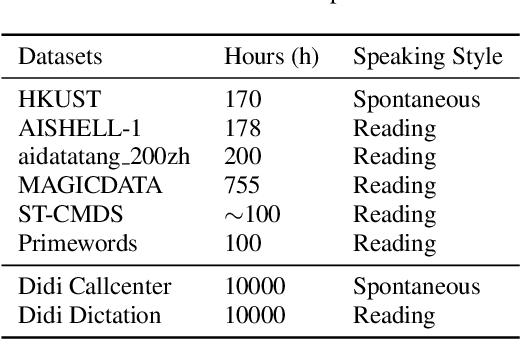
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.
* Submitted to ICASSP 2020
View paper on