 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIST: Unpaired Neural Implicit Shape Translation Network
Paper and Code

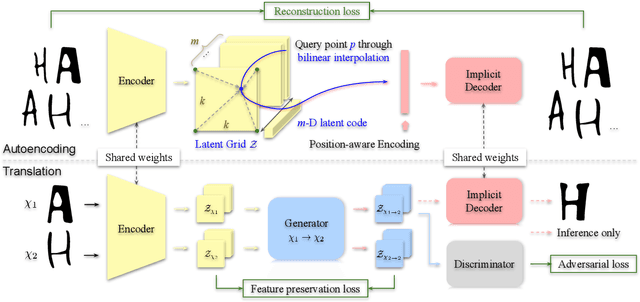
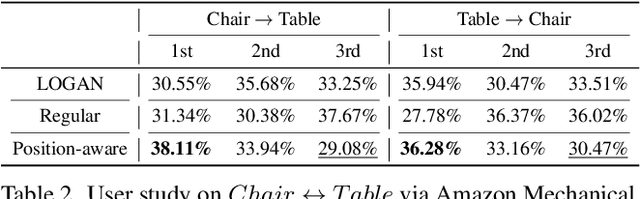
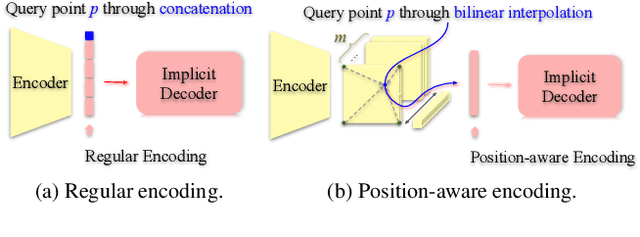
We introduce UNIST, the first deep neural implicit model for general-purpose, unpaired shape-to-shape translation, in both 2D and 3D domains. Our model is built on autoencoding implicit fields, rather than point clouds which represents the state of the art. Furthermore, our translation network is trained to perform the task over a latent grid representation which combines the merits of both latent-space processing and position awareness, to not only enable drastic shape transforms but also well preserve spatial features and fine local details for natural shape translations. With the same network architecture and only dictated by the input domain pairs, our model can learn both style-preserving content alteration and content-preserving style transfer. We demonstrate the generality and quality of the translation results, and compare them to well-known baselines.