 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJigsawPlan: Room Layout Jigsaw Puzzle Extreme Structure from Motion using Diffusion Models
Nov 24, 2022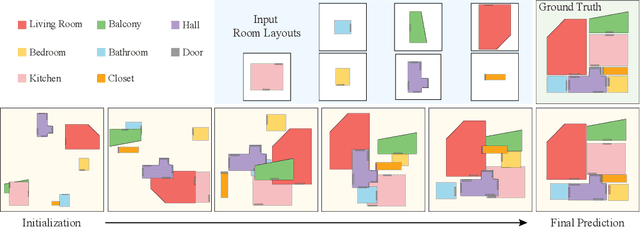

This paper presents a novel approach to the Extreme Structure from Motion (E-SfM) problem, which takes a set of room layouts as polygonal curves in the top-down view, and aligns the room layout pieces by estimating their 2D translations and rotations, akin to solving the jigsaw puzzle of room layouts. The biggest discovery and surprise of the paper is that the simple use of a Diffusion Model solves this challenging registration problem as a conditional generation process. The paper presents a new dataset of room layouts and floorplans for 98,780 houses. The qualitative and quantitative evaluations demonstrate that the proposed approach outperforms the competing methods by significant margins.
HouseDiffusion: Vector Floorplan Generation via a Diffusion Model with Discrete and Continuous Denoising
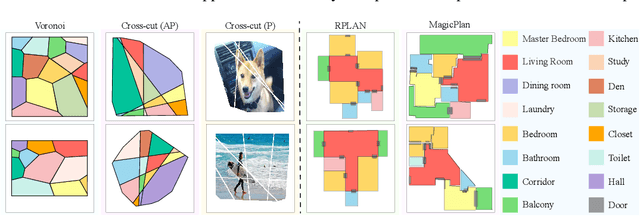
Nov 23, 2022The paper presents a novel approach for vector-floorplan generation via a diffusion model, which denoises 2D coordinates of room/door corners with two inference objectives: 1) a single-step noise as the continuous quantity to precisely invert the continuous forward process; and 2) the final 2D coordinate as the discrete quantity to establish geometric incident relationships such as parallelism, orthogonality, and corner-sharing. Our task is graph-conditioned floorplan generation, a common workflow in floorplan design. We represent a floorplan as 1D polygonal loops, each of which corresponds to a room or a door. Our diffusion model employs a Transformer architecture at the core, which controls the attention masks based on the input graph-constraint and directly generates vector-graphics floorplans via a discrete and continuous denoising process. We have evaluated our approach on RPLAN dataset. The proposed approach makes significant improvements in all the metrics against the state-of-the-art with significant margins, while being capable of generating non-Manhattan structures and controlling the exact number of corners per room. A project website with supplementary video and document is here https://aminshabani.github.io/housediffusion.
Distill-2MD-MTL: Data Distillation based on Multi-Dataset Multi-Domain Multi-Task Frame Work to Solve Face Related Tasksks, Multi Task Learning, Semi-Supervised Learning
Jul 09, 2019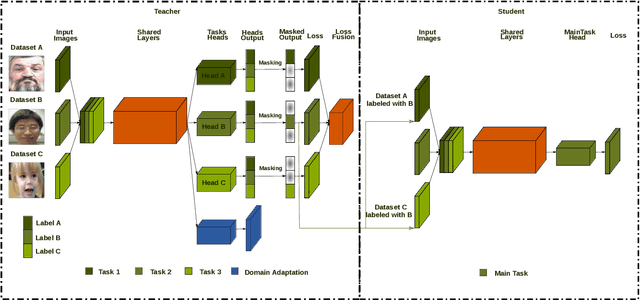
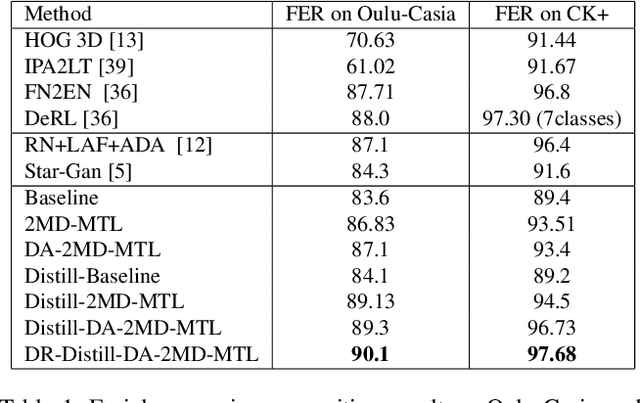

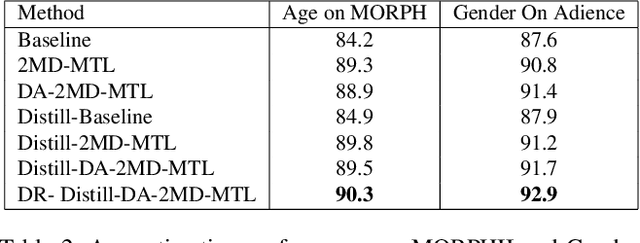
We propose a new semi-supervised learning method on face-related tasks based on Multi-Task Learning (MTL) and data distillation. The proposed method exploits multiple datasets with different labels for different-but-related tasks such as simultaneous age, gender, race, facial expression estimation. Specifically, when there are only a few well-labeled data for a specific task among the multiple related ones, we exploit the labels of other related tasks in different domains. Our approach is composed of (1) a new MTL method which can deal with weakly labeled datasets and perform several tasks simultaneously, and (2) an MTL-based data distillation framework which enables network generalization for the training and test data from different domains. Experiments show that the proposed multi-task system performs each task better than the baseline single task. It is also demonstrated that using different domain datasets along with the main dataset can enhance network generalization and overcome the domain differences between datasets. Also, comparing data distillation both on the baseline and MTL framework, the latter shows more accurate predictions on unlabeled data from different domains. Furthermore, by proposing a new learning-rate optimization method, our proposed network is able to dynamically tune its learning rate.
Local Visual Microphones: Improved Sound Extraction from Silent Video
Jan 29, 2018
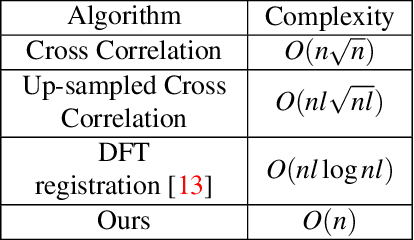


Sound waves cause small vibrations in nearby objects. A few techniques exist in the literature that can extract sound from video. In this paper we study local vibration patterns at different image locations. We show that different locations in the image vibrate differently. We carefully aggregate local vibrations and produce a sound quality that improves state-of-the-art. We show that local vibrations could have a time delay because sound waves take time to travel through the air. We use this phenomenon to estimate sound direction. We also present a novel algorithm that speeds up sound extraction by two to three orders of magnitude and reaches real-time performance in a 20KHz video.