 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2KQL: From Natural Language to Kusto Query
Apr 03, 2024



Data is growing rapidly in volume and complexity. Proficiency in database query languages is pivotal for crafting effective queries. As coding assistants become more prevalent, there is significant opportunity to enhance database query languages. The Kusto Query Language (KQL) is a widely used query language for large semi-structured data such as logs, telemetries, and time-series for big data analytics platforms. This paper introduces NL2KQL an innovative framework that uses large language models (LLMs) to convert natural language queries (NLQs) to KQL queries. The proposed NL2KQL framework includes several key components: Schema Refiner which narrows down the schema to its most pertinent elements; the Few-shot Selector which dynamically selects relevant examples from a few-shot dataset; and the Query Refiner which repairs syntactic and semantic errors in KQL queries. Additionally, this study outlines a method for generating large datasets of synthetic NLQ-KQL pairs which are valid within a specific database contexts. To validate NL2KQL's performance, we utilize an array of online (based on query execution) and offline (based on query parsing) metrics. Through ablation studies, the significance of each framework component is examined, and the datasets used for benchmarking are made publicly available. This work is the first of its kind and is compared with available baselines to demonstrate its effectiveness.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

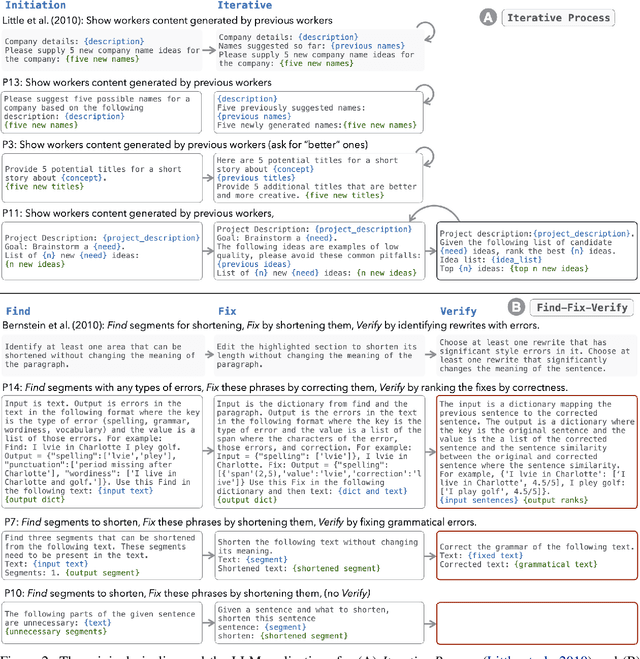
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.