 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDICE: Discrete Interpretable Comparative Evaluation with Probabilistic Scoring for Retrieval-Augmented Generation
Dec 27, 2025As Retrieval-Augmented Generation (RAG) systems evolve toward more sophisticated architectures, ensuring their trustworthiness through explainable and robust evaluation becomes critical. Existing scalar metrics suffer from limited interpretability, inadequate uncertainty quantification, and computational inefficiency in multi-system comparisons, hindering responsible deployment of RAG technologies. We introduce DICE (Discrete Interpretable Comparative Evaluation), a two-stage, evidence-coupled framework that advances explainability and robustness in RAG evaluation. DICE combines deep analytical reasoning with probabilistic $\{A, B, Tie\}$ scoring to produce transparent, confidence-aware judgments that support accountable system improvement through interpretable reasoning traces, enabling systematic error diagnosis and actionable insights. To address efficiency challenges at scale, DICE employs a Swiss-system tournament that reduces computational complexity from $O(N^2)$ to $O(N \log N)$, achieving a 42.9% reduction in our eight-system evaluation while preserving ranking fidelity. Validation on a curated Chinese financial QA dataset demonstrates that DICE achieves 85.7% agreement with human experts, substantially outperforming existing LLM-based metrics such as RAGAS. Our results establish DICE as a responsible, explainable, and efficient paradigm for trustworthy RAG system assessment.
FluentLip: A Phonemes-Based Two-stage Approach for Audio-Driven Lip Synthesis with Optical Flow Consistency
Apr 06, 2025Generating consecutive images of lip movements that align with a given speech in audio-driven lip synthesis is a challenging task. While previous studies have made strides in synchronization and visual quality, lip intelligibility and video fluency remain persistent challenges. This work proposes FluentLip, a two-stage approach for audio-driven lip synthesis, incorporating three featured strategies. To improve lip synchronization and intelligibility, we integrate a phoneme extractor and encoder to generate a fusion of audio and phoneme information for multimodal learning. Additionally, we employ optical flow consistency loss to ensure natural transitions between image frames. Furthermore, we incorporate a diffusion chain during the training of Generative Adversarial Networks (GANs) to improve both stability and efficiency. We evaluate our proposed FluentLip through extensive experiments, comparing it with five state-of-the-art (SOTA) approaches across five metrics, including a proposed metric called Phoneme Error Rate (PER) that evaluates lip pose intelligibility and video fluency. The experimental results demonstrate that our FluentLip approach is highly competitive, achieving significant improvements in smoothness and naturalness. In particular, it outperforms these SOTA approaches by approximately $\textbf{16.3%}$ in Fr\'echet Inception Distance (FID) and $\textbf{35.2%}$ in PER.
SNAP: Stopping Catastrophic Forgetting in Hebbian Learning with Sigmoidal Neuronal Adaptive Plasticity
Oct 20, 2024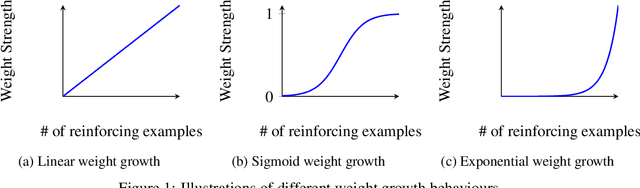



Artificial Neural Networks (ANNs) suffer from catastrophic forgetting, where the learning of new tasks causes the catastrophic forgetting of old tasks. Existing Machine Learning (ML) algorithms, including those using Stochastic Gradient Descent (SGD) and Hebbian Learning typically update their weights linearly with experience i.e., independently of their current strength. This contrasts with biological neurons, which at intermediate strengths are very plastic, but consolidate with Long-Term Potentiation (LTP) once they reach a certain strength. We hypothesize this mechanism might help mitigate catastrophic forgetting. We introduce Sigmoidal Neuronal Adaptive Plasticity (SNAP) an artificial approximation to Long-Term Potentiation for ANNs by having the weights follow a sigmoidal growth behaviour allowing the weights to consolidate and stabilize when they reach sufficiently large or small values. We then compare SNAP to linear weight growth and exponential weight growth and see that SNAP completely prevents the forgetting of previous tasks for Hebbian Learning but not for SGD-base learning.