 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Hard Writes and Rigid Preservation: Soft Recursive Least-Squares for Lifelong LLM Editing
Jan 22, 2026Model editing updates a pre-trained LLM with new facts or rules without re-training, while preserving unrelated behavior. In real deployment, edits arrive as long streams, and existing editors often face a plasticity-stability dilemma: locate-then-edit "hard writes" can accumulate interference over time, while null-space-style "hard preservation" preserves only what is explicitly constrained, so past edits can be overwritten and unconstrained behaviors may deviate, degrading general capabilities in the many-edits regime. We propose RLSEdit, a recursive least-squares editor for long sequential editing. RLSEdit formulates editing as an online quadratic optimization with soft constraints, minimizing a cumulative key-value fitting objective with two regularizers that control for both deviation from the pre-trained weights and from a designated anchor mapping. The resulting update admits an efficient online recursion via the Woodbury identity, with per-edit cost independent of history length and scaling only with the current edit size. We further provide deviation bounds and an asymptotic characterization of the adherence-preservation trade-off in the many-edits regime. Experiments on multiple model families demonstrate stable scaling to 10K edits, outperforming strong baselines in both edit success and holistic stability -- crucially retaining early edits, and preserving general capabilities on GLUE and held-out reasoning/code benchmarks.
SNAP: Stopping Catastrophic Forgetting in Hebbian Learning with Sigmoidal Neuronal Adaptive Plasticity
Oct 20, 2024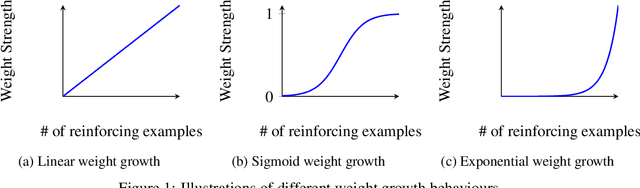



Artificial Neural Networks (ANNs) suffer from catastrophic forgetting, where the learning of new tasks causes the catastrophic forgetting of old tasks. Existing Machine Learning (ML) algorithms, including those using Stochastic Gradient Descent (SGD) and Hebbian Learning typically update their weights linearly with experience i.e., independently of their current strength. This contrasts with biological neurons, which at intermediate strengths are very plastic, but consolidate with Long-Term Potentiation (LTP) once they reach a certain strength. We hypothesize this mechanism might help mitigate catastrophic forgetting. We introduce Sigmoidal Neuronal Adaptive Plasticity (SNAP) an artificial approximation to Long-Term Potentiation for ANNs by having the weights follow a sigmoidal growth behaviour allowing the weights to consolidate and stabilize when they reach sufficiently large or small values. We then compare SNAP to linear weight growth and exponential weight growth and see that SNAP completely prevents the forgetting of previous tasks for Hebbian Learning but not for SGD-base learning.