 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse Inspired Federated Learning with Non-iid Data
Paper and Code
Mar 31, 2023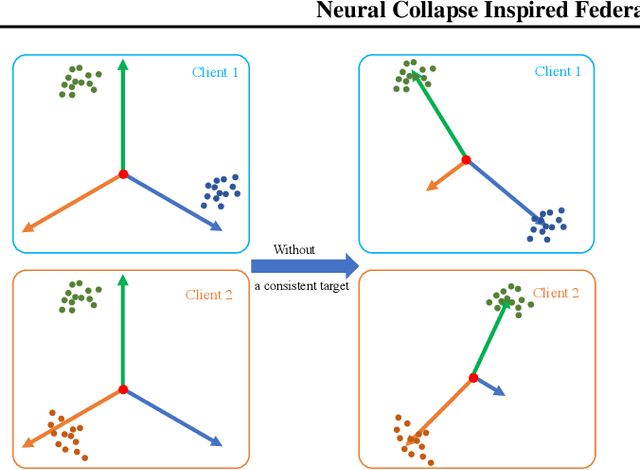
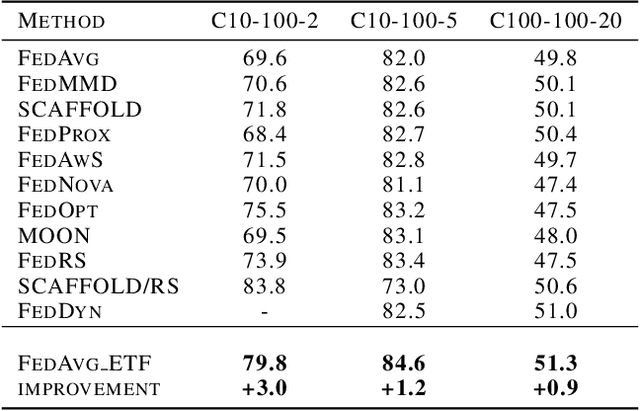
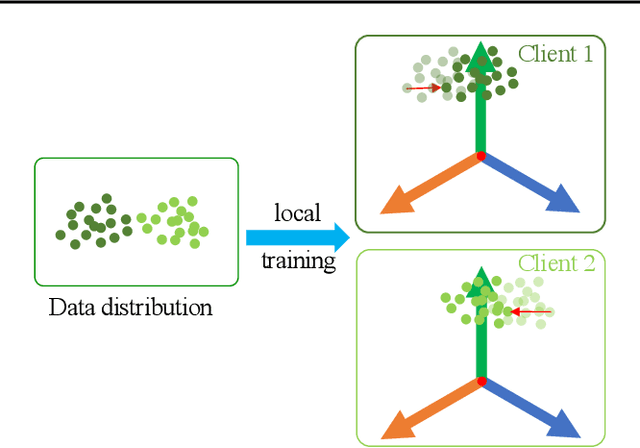
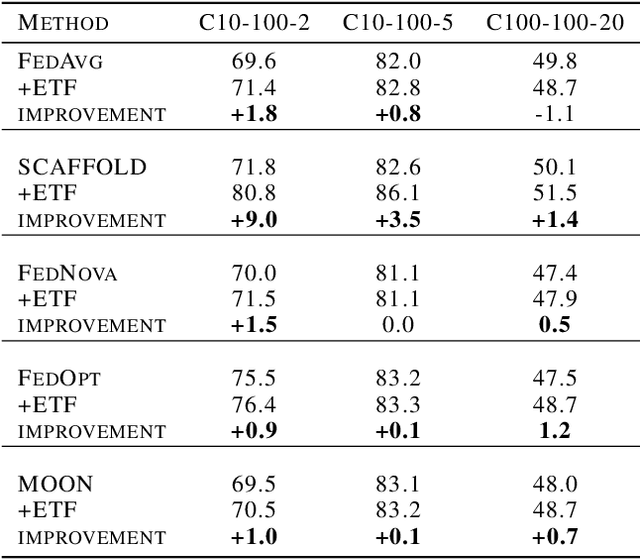
One of the challenges in federated learning is the non-independent and identically distributed (non-iid) characteristics between heterogeneous devices, which cause significant differences in local updates and affect the performance of the central server. Although many studies have been proposed to address this challenge, they only focus on local training and aggregation processes to smooth the changes and fail to achieve high performance with deep learning models. Inspired by the phenomenon of neural collapse, we force each client to be optimized toward an optimal global structure for classification. Specifically, we initialize it as a random simplex Equiangular Tight Frame (ETF) and fix it as the unit optimization target of all clients during the local updating. After guaranteeing all clients are learning to converge to the global optimum, we propose to add a global memory vector for each category to remedy the parameter fluctuation caused by the bias of the intra-class condition distribution among clients. Our experimental results show that our method can improve the performance with faster convergence speed on different-size datasets.