 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection
Dec 20, 2022Compared to typical multi-sensor systems, monocular 3D object detection has attracted much attention due to its simple configuration. However, there is still a significant gap between LiDAR-based and monocular-based methods. In this paper, we find that the ill-posed nature of monocular imagery can lead to depth ambiguity. Specifically, objects with different depths can appear with the same bounding boxes and similar visual features in the 2D image. Unfortunately, the network cannot accurately distinguish different depths from such non-discriminative visual features, resulting in unstable depth training. To facilitate depth learning, we propose a simple yet effective plug-and-play module, One Bounding Box Multiple Objects (OBMO). Concretely, we add a set of suitable pseudo labels by shifting the 3D bounding box along the viewing frustum. To constrain the pseudo-3D labels to be reasonable, we carefully design two label scoring strategies to represent their quality. In contrast to the original hard depth labels, such soft pseudo labels with quality scores allow the network to learn a reasonable depth range, boosting training stability and thus improving final performance. Extensive experiments on KITTI and Waymo benchmarks show that our method significantly improves state-of-the-art monocular 3D detectors by a significant margin (The improvements under the moderate setting on KITTI validation set are $\mathbf{1.82\sim 10.91\%}$ mAP in BEV and $\mathbf{1.18\sim 9.36\%}$ mAP in 3D}. Codes have been released at https://github.com/mrsempress/OBMO.
Towards In-distribution Compatibility in Out-of-distribution Detection
Aug 29, 2022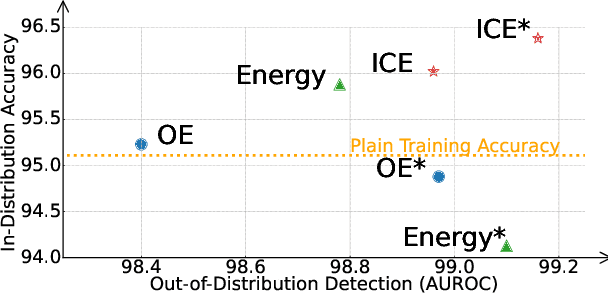
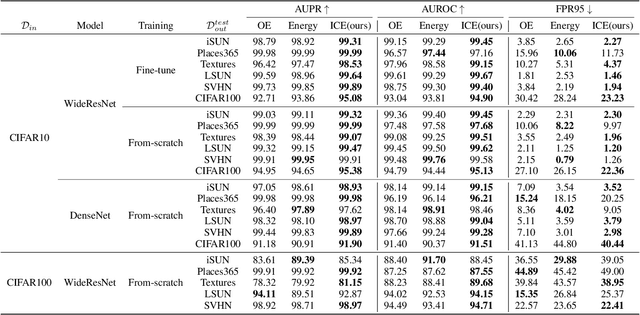
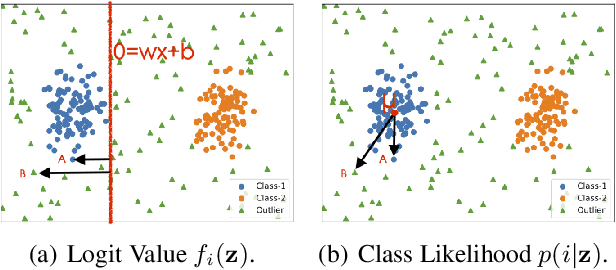
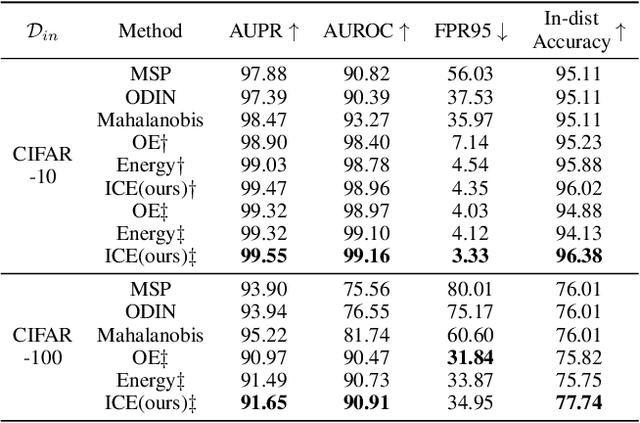
Deep neural network, despite its remarkable capability of discriminating targeted in-distribution samples, shows poor performance on detecting anomalous out-of-distribution data. To address this defect, state-of-the-art solutions choose to train deep networks on an auxiliary dataset of outliers. Various training criteria for these auxiliary outliers are proposed based on heuristic intuitions. However, we find that these intuitively designed outlier training criteria can hurt in-distribution learning and eventually lead to inferior performance. To this end, we identify three causes of the in-distribution incompatibility: contradictory gradient, false likelihood, and distribution shift. Based on our new understandings, we propose a new out-of-distribution detection method by adapting both the top-design of deep models and the loss function. Our method achieves in-distribution compatibility by pursuing less interference with the probabilistic characteristic of in-distribution features. On several benchmarks, our method not only achieves the state-of-the-art out-of-distribution detection performance but also improves the in-distribution accuracy.