 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Glyph-driven Topology Enhancement Network for Scene Text Recognition
Paper and Code
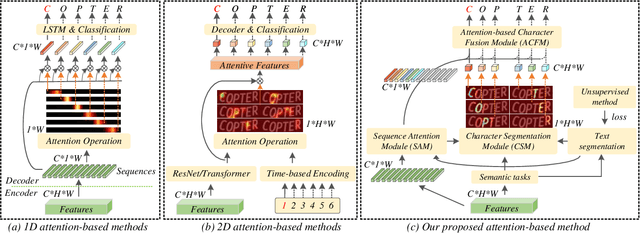
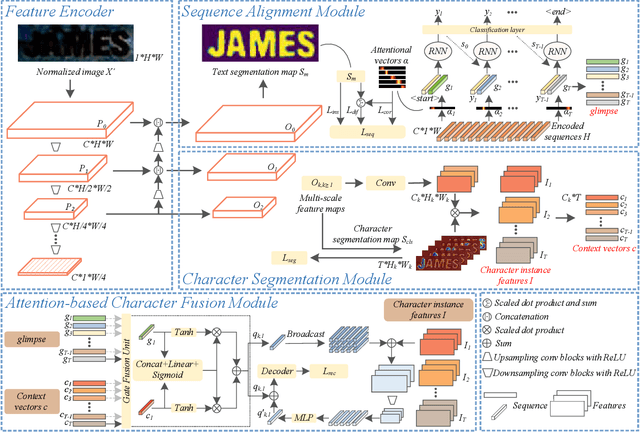
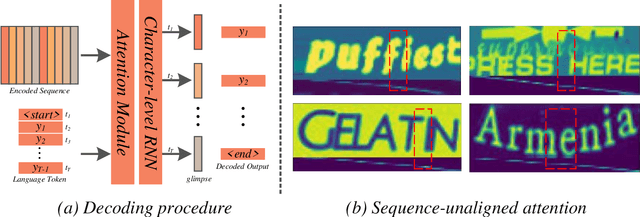

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.