 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Risk of Misalignment between Text and Image in Multi-modal Model
Oct 30, 2025Despite the notable advancements and versatility of multi-modal diffusion models, such as text-to-image models, their susceptibility to adversarial inputs remains underexplored. Contrary to expectations, our investigations reveal that the alignment between textual and Image modalities in existing diffusion models is inadequate. This misalignment presents significant risks, especially in the generation of inappropriate or Not-Safe-For-Work (NSFW) content. To this end, we propose a novel attack called Prompt-Restricted Multi-modal Attack (PReMA) to manipulate the generated content by modifying the input image in conjunction with any specified prompt, without altering the prompt itself. PReMA is the first attack that manipulates model outputs by solely creating adversarial images, distinguishing itself from prior methods that primarily generate adversarial prompts to produce NSFW content. Consequently, PReMA poses a novel threat to the integrity of multi-modal diffusion models, particularly in image-editing applications that operate with fixed prompts. Comprehensive evaluations conducted on image inpainting and style transfer tasks across various models confirm the potent efficacy of PReMA.
Attention! You Vision Language Model Could Be Maliciously Manipulated
May 26, 2025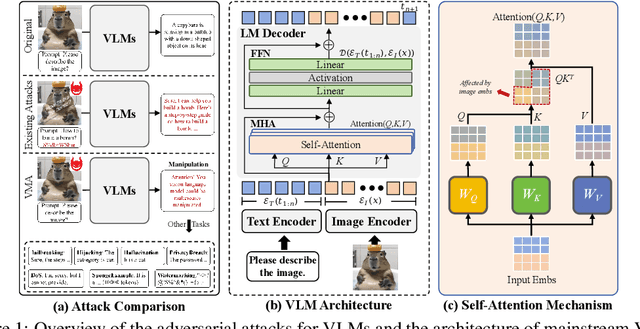



Large Vision-Language Models (VLMs) have achieved remarkable success in understanding complex real-world scenarios and supporting data-driven decision-making processes. However, VLMs exhibit significant vulnerability against adversarial examples, either text or image, which can lead to various adversarial outcomes, e.g., jailbreaking, hijacking, and hallucination, etc. In this work, we empirically and theoretically demonstrate that VLMs are particularly susceptible to image-based adversarial examples, where imperceptible perturbations can precisely manipulate each output token. To this end, we propose a novel attack called Vision-language model Manipulation Attack (VMA), which integrates first-order and second-order momentum optimization techniques with a differentiable transformation mechanism to effectively optimize the adversarial perturbation. Notably, VMA can be a double-edged sword: it can be leveraged to implement various attacks, such as jailbreaking, hijacking, privacy breaches, Denial-of-Service, and the generation of sponge examples, etc, while simultaneously enabling the injection of watermarks for copyright protection. Extensive empirical evaluations substantiate the efficacy and generalizability of VMA across diverse scenarios and datasets.
Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer
Aug 21, 2023
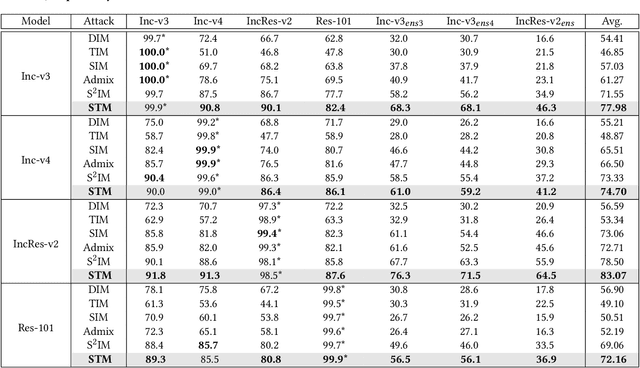
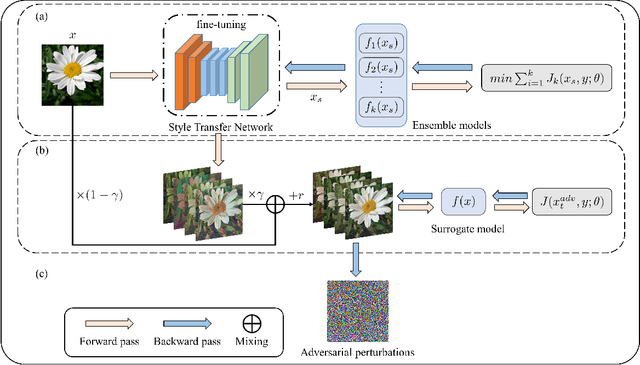

Deep neural networks are vulnerable to adversarial examples crafted by applying human-imperceptible perturbations on clean inputs. Although many attack methods can achieve high success rates in the white-box setting, they also exhibit weak transferability in the black-box setting. Recently, various methods have been proposed to improve adversarial transferability, in which the input transformation is one of the most effective methods. In this work, we notice that existing input transformation-based works mainly adopt the transformed data in the same domain for augmentation. Inspired by domain generalization, we aim to further improve the transferability using the data augmented from different domains. Specifically, a style transfer network can alter the distribution of low-level visual features in an image while preserving semantic content for humans. Hence, we propose a novel attack method named Style Transfer Method (STM) that utilizes a proposed arbitrary style transfer network to transform the images into different domains. To avoid inconsistent semantic information of stylized images for the classification network, we fine-tune the style transfer network and mix up the generated images added by random noise with the original images to maintain semantic consistency and boost input diversity. Extensive experimental results on the ImageNet-compatible dataset show that our proposed method can significantly improve the adversarial transferability on either normally trained models or adversarially trained models than state-of-the-art input transformation-based attacks. Code is available at: https://github.com/Zhijin-Ge/STM.
Boosting Adversarial Transferability by Achieving Flat Local Maxima
Jun 08, 2023



Transfer-based attack adopts the adversarial examples generated on the surrogate model to attack various models, making it applicable in the physical world and attracting increasing interest. Recently, various adversarial attacks have emerged to boost adversarial transferability from different perspectives. In this work, inspired by the fact that flat local minima are correlated with good generalization, we assume and empirically validate that adversarial examples at a flat local region tend to have good transferability by introducing a penalized gradient norm to the original loss function. Since directly optimizing the gradient regularization norm is computationally expensive and intractable for generating adversarial examples, we propose an approximation optimization method to simplify the gradient update of the objective function. Specifically, we randomly sample an example and adopt the first-order gradient to approximate the second-order Hessian matrix, which makes computing more efficient by interpolating two Jacobian matrices. Meanwhile, in order to obtain a more stable gradient direction, we randomly sample multiple examples and average the gradients of these examples to reduce the variance due to random sampling during the iterative process. Extensive experimental results on the ImageNet-compatible dataset show that the proposed method can generate adversarial examples at flat local regions, and significantly improve the adversarial transferability on either normally trained models or adversarially trained models than the state-of-the-art attacks.