 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
Hybrid Feature Embedding For Automatic Building Outline Extraction
Jul 20, 2023
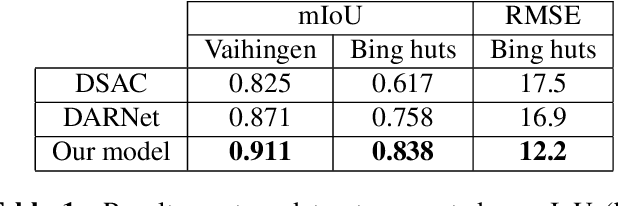

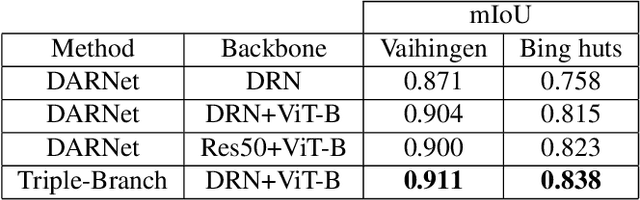
Building outline extracted from high-resolution aerial images can be used in various application fields such as change detection and disaster assessment. However, traditional CNN model cannot recognize contours very precisely from original images. In this paper, we proposed a CNN and Transformer based model together with active contour model to deal with this problem. We also designed a triple-branch decoder structure to handle different features generated by encoder. Experiment results show that our model outperforms other baseline model on two datasets, achieving 91.1% mIoU on Vaihingen and 83.8% on Bing huts.