 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model
Paper and Code
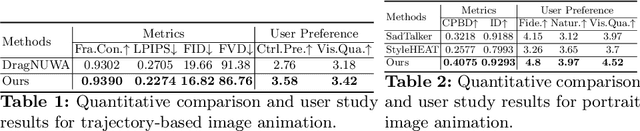
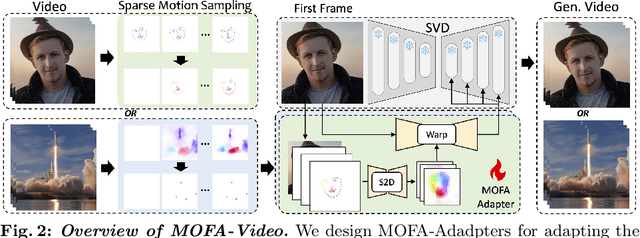
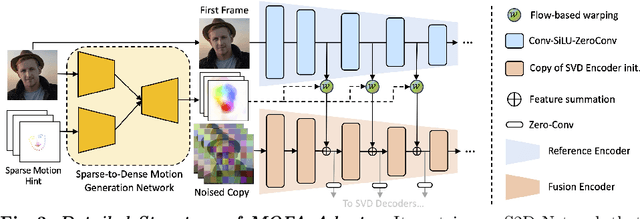

We present MOFA-Video, an advanced controllable image animation method that generates video from the given image using various additional controllable signals (such as human landmarks reference, manual trajectories, and another even provided video) or their combinations. This is different from previous methods which only can work on a specific motion domain or show weak control abilities with diffusion prior. To achieve our goal, we design several domain-aware motion field adapters (\ie, MOFA-Adapters) to control the generated motions in the video generation pipeline. For MOFA-Adapters, we consider the temporal motion consistency of the video and generate the dense motion flow from the given sparse control conditions first, and then, the multi-scale features of the given image are wrapped as a guided feature for stable video diffusion generation. We naively train two motion adapters for the manual trajectories and the human landmarks individually since they both contain sparse information about the control. After training, the MOFA-Adapters in different domains can also work together for more controllable video generation. Project Page: https://myniuuu.github.io/MOFA_Video/