 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying View of Coverage in Linear Off-Policy Evaluation
Jan 26, 2026Off-policy evaluation (OPE) is a fundamental task in reinforcement learning (RL). In the classic setting of linear OPE, finite-sample guarantees often take the form $$ \textrm{Evaluation error} \le \textrm{poly}(C^π, d, 1/n,\log(1/δ)), $$ where $d$ is the dimension of the features and $C^π$ is a coverage parameter that characterizes the degree to which the visited features lie in the span of the data distribution. While such guarantees are well-understood for several popular algorithms under stronger assumptions (e.g. Bellman completeness), the understanding is lacking and fragmented in the minimal setting where only the target value function is linearly realizable in the features. Despite recent interest in tight characterizations of the statistical rate in this setting, the right notion of coverage remains unclear, and candidate definitions from prior analyses have undesirable properties and are starkly disconnected from more standard definitions in the literature. We provide a novel finite-sample analysis of a canonical algorithm for this setting, LSTDQ. Inspired by an instrumental-variable view, we develop error bounds that depend on a novel coverage parameter, the feature-dynamics coverage, which can be interpreted as linear coverage in an induced dynamical system for feature evolution. With further assumptions -- such as Bellman-completeness -- our definition successfully recovers the coverage parameters specialized to those settings, finally yielding a unified understanding for coverage in linear OPE.
Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
Feb 11, 2025



Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). In this work we focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Our contributions are two fold. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation of candidate value functions, better control of misspecification, and evaluation of model-free and model-based methods alike. We exemplify the protocol on a Gym environment, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.
Reinforcement Learning under Latent Dynamics: Toward Statistical and Algorithmic Modularity
Oct 23, 2024
Real-world applications of reinforcement learning often involve environments where agents operate on complex, high-dimensional observations, but the underlying (''latent'') dynamics are comparatively simple. However, outside of restrictive settings such as small latent spaces, the fundamental statistical requirements and algorithmic principles for reinforcement learning under latent dynamics are poorly understood. This paper addresses the question of reinforcement learning under $\textit{general}$ latent dynamics from a statistical and algorithmic perspective. On the statistical side, our main negative result shows that most well-studied settings for reinforcement learning with function approximation become intractable when composed with rich observations; we complement this with a positive result, identifying latent pushforward coverability as a general condition that enables statistical tractability. Algorithmically, we develop provably efficient observable-to-latent reductions -- that is, reductions that transform an arbitrary algorithm for the latent MDP into an algorithm that can operate on rich observations -- in two settings: one where the agent has access to hindsight observations of the latent dynamics [LADZ23], and one where the agent can estimate self-predictive latent models [SAGHCB20]. Together, our results serve as a first step toward a unified statistical and algorithmic theory for reinforcement learning under latent dynamics.
Scalable Online Exploration via Coverability
Mar 11, 2024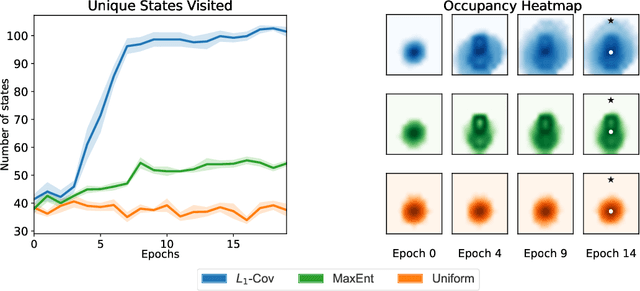



Exploration is a major challenge in reinforcement learning, especially for high-dimensional domains that require function approximation. We propose exploration objectives -- policy optimization objectives that enable downstream maximization of any reward function -- as a conceptual framework to systematize the study of exploration. Within this framework, we introduce a new objective, $L_1$-Coverage, which generalizes previous exploration schemes and supports three fundamental desiderata: 1. Intrinsic complexity control. $L_1$-Coverage is associated with a structural parameter, $L_1$-Coverability, which reflects the intrinsic statistical difficulty of the underlying MDP, subsuming Block and Low-Rank MDPs. 2. Efficient planning. For a known MDP, optimizing $L_1$-Coverage efficiently reduces to standard policy optimization, allowing flexible integration with off-the-shelf methods such as policy gradient and Q-learning approaches. 3. Efficient exploration. $L_1$-Coverage enables the first computationally efficient model-based and model-free algorithms for online (reward-free or reward-driven) reinforcement learning in MDPs with low coverability. Empirically, we find that $L_1$-Coverage effectively drives off-the-shelf policy optimization algorithms to explore the state space.
Mitigating Covariate Shift in Misspecified Regression with Applications to Reinforcement Learning
Jan 22, 2024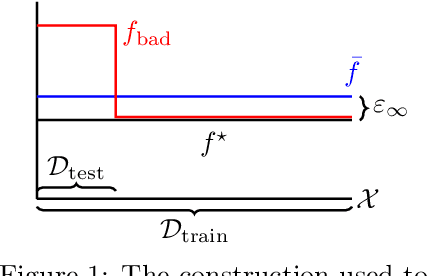
A pervasive phenomenon in machine learning applications is distribution shift, where training and deployment conditions for a machine learning model differ. As distribution shift typically results in a degradation in performance, much attention has been devoted to algorithmic interventions that mitigate these detrimental effects. In this paper, we study the effect of distribution shift in the presence of model misspecification, specifically focusing on $L_{\infty}$-misspecified regression and adversarial covariate shift, where the regression target remains fixed while the covariate distribution changes arbitrarily. We show that empirical risk minimization, or standard least squares regression, can result in undesirable misspecification amplification where the error due to misspecification is amplified by the density ratio between the training and testing distributions. As our main result, we develop a new algorithm -- inspired by robust optimization techniques -- that avoids this undesirable behavior, resulting in no misspecification amplification while still obtaining optimal statistical rates. As applications, we use this regression procedure to obtain new guarantees in offline and online reinforcement learning with misspecification and establish new separations between previously studied structural conditions and notions of coverage.
Harnessing Density Ratios for Online Reinforcement Learning
Jan 18, 2024The theories of offline and online reinforcement learning, despite having evolved in parallel, have begun to show signs of the possibility for a unification, with algorithms and analysis techniques for one setting often having natural counterparts in the other. However, the notion of density ratio modeling, an emerging paradigm in offline RL, has been largely absent from online RL, perhaps for good reason: the very existence and boundedness of density ratios relies on access to an exploratory dataset with good coverage, but the core challenge in online RL is to collect such a dataset without having one to start. In this work we show -- perhaps surprisingly -- that density ratio-based algorithms have online counterparts. Assuming only the existence of an exploratory distribution with good coverage, a structural condition known as coverability (Xie et al., 2023), we give a new algorithm (GLOW) that uses density ratio realizability and value function realizability to perform sample-efficient online exploration. GLOW addresses unbounded density ratios via careful use of truncation, and combines this with optimism to guide exploration. GLOW is computationally inefficient; we complement it with a more efficient counterpart, HyGLOW, for the Hybrid RL setting (Song et al., 2022) wherein online RL is augmented with additional offline data. HyGLOW is derived as a special case of a more general meta-algorithm that provides a provable black-box reduction from hybrid RL to offline RL, which may be of independent interest.
The Optimal Approximation Factors in Misspecified Off-Policy Value Function Estimation
Jul 25, 2023
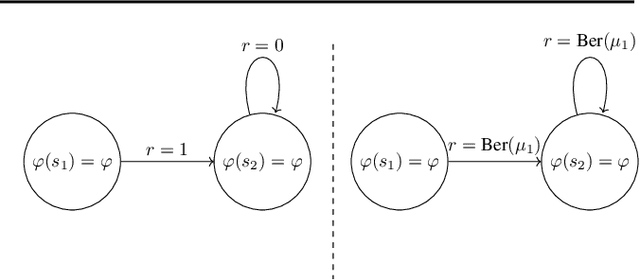
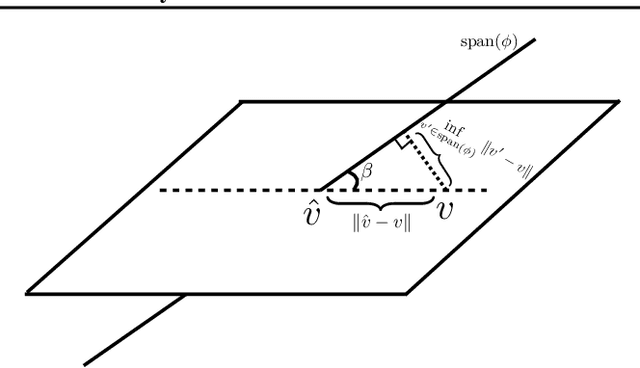
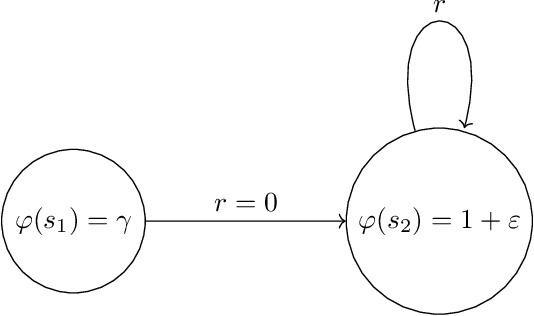
Theoretical guarantees in reinforcement learning (RL) are known to suffer multiplicative blow-up factors with respect to the misspecification error of function approximation. Yet, the nature of such \emph{approximation factors} -- especially their optimal form in a given learning problem -- is poorly understood. In this paper we study this question in linear off-policy value function estimation, where many open questions remain. We study the approximation factor in a broad spectrum of settings, such as with the weighted $L_2$-norm (where the weighting is the offline state distribution), the $L_\infty$ norm, the presence vs. absence of state aliasing, and full vs. partial coverage of the state space. We establish the optimal asymptotic approximation factors (up to constants) for all of these settings. In particular, our bounds identify two instance-dependent factors for the $L_2(\mu)$ norm and only one for the $L_\infty$ norm, which are shown to dictate the hardness of off-policy evaluation under misspecification.
A Few Expert Queries Suffices for Sample-Efficient RL with Resets and Linear Value Approximation
Jul 18, 2022
The current paper studies sample-efficient Reinforcement Learning (RL) in settings where only the optimal value function is assumed to be linearly-realizable. It has recently been understood that, even under this seemingly strong assumption and access to a generative model, worst-case sample complexities can be prohibitively (i.e., exponentially) large. We investigate the setting where the learner additionally has access to interactive demonstrations from an expert policy, and we present a statistically and computationally efficient algorithm (Delphi) for blending exploration with expert queries. In particular, Delphi requires $\tilde{\mathcal{O}}(d)$ expert queries and a $\texttt{poly}(d,H,|\mathcal{A}|,1/\varepsilon)$ amount of exploratory samples to provably recover an $\varepsilon$-suboptimal policy. Compared to pure RL approaches, this corresponds to an exponential improvement in sample complexity with surprisingly-little expert input. Compared to prior imitation learning (IL) approaches, our required number of expert demonstrations is independent of $H$ and logarithmic in $1/\varepsilon$, whereas all prior work required at least linear factors of both in addition to the same dependence on $d$. Towards establishing the minimal amount of expert queries needed, we show that, in the same setting, any learner whose exploration budget is polynomially-bounded (in terms of $d,H,$ and $|\mathcal{A}|$) will require at least $\tilde\Omega(\sqrt{d})$ oracle calls to recover a policy competing with the expert's value function. Under the weaker assumption that the expert's policy is linear, we show that the lower bound increases to $\tilde\Omega(d)$.
On Query-efficient Planning in MDPs under Linear Realizability of the Optimal State-value Function
Feb 04, 2021We consider the problem of local planning in fixed-horizon Markov Decision Processes (MDPs) with a generative model under the assumption that the optimal value function lies in the span of a feature map that is accessible through the generative model. As opposed to previous work where linear realizability of all policies was assumed, we consider the significantly relaxed assumption of a single linearly realizable (deterministic) policy. A recent lower bound established that the related problem when the action-value function of the optimal policy is linearly realizable requires an exponential number of queries, either in H (the horizon of the MDP) or d (the dimension of the feature mapping). Their construction crucially relies on having an exponentially large action set. In contrast, in this work, we establish that poly$(H, d)$ learning is possible (with state value function realizability) whenever the action set is small (i.e. O(1)). In particular, we present the TensorPlan algorithm which uses poly$((dH/\delta)^A)$ queries to find a $\delta$-optimal policy relative to any deterministic policy for which the value function is linearly realizable with a parameter from a fixed radius ball around zero. This is the first algorithm to give a polynomial query complexity guarantee using only linear-realizability of a single competing value function. Whether the computation cost is similarly bounded remains an interesting open question. The upper bound is complemented by a lower bound which proves that in the infinite-horizon episodic setting, planners that achieve constant suboptimality need exponentially many queries, either in the dimension or the number of actions.
A Variant of the Wang-Foster-Kakade Lower Bound for the Discounted Setting
Nov 04, 2020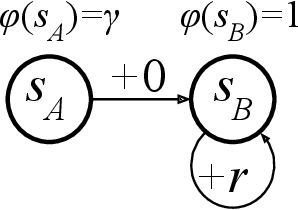
Recently, Wang et al. (2020) showed a highly intriguing hardness result for batch reinforcement learning (RL) with linearly realizable value function and good feature coverage in the finite-horizon case. In this note we show that once adapted to the discounted setting, the construction can be simplified to a 2-state MDP with 1-dimensional features, such that learning is impossible even with an infinite amount of data.