Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variant of the Wang-Foster-Kakade Lower Bound for the Discounted Setting
Paper and Code
Nov 04, 2020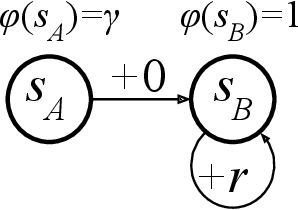
Recently, Wang et al. (2020) showed a highly intriguing hardness result for batch reinforcement learning (RL) with linearly realizable value function and good feature coverage in the finite-horizon case. In this note we show that once adapted to the discounted setting, the construction can be simplified to a 2-state MDP with 1-dimensional features, such that learning is impossible even with an infinite amount of data.
View paper on