 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Covariate Shift in Misspecified Regression with Applications to Reinforcement Learning
Paper and Code
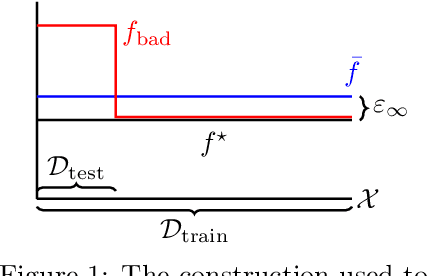
A pervasive phenomenon in machine learning applications is distribution shift, where training and deployment conditions for a machine learning model differ. As distribution shift typically results in a degradation in performance, much attention has been devoted to algorithmic interventions that mitigate these detrimental effects. In this paper, we study the effect of distribution shift in the presence of model misspecification, specifically focusing on $L_{\infty}$-misspecified regression and adversarial covariate shift, where the regression target remains fixed while the covariate distribution changes arbitrarily. We show that empirical risk minimization, or standard least squares regression, can result in undesirable misspecification amplification where the error due to misspecification is amplified by the density ratio between the training and testing distributions. As our main result, we develop a new algorithm -- inspired by robust optimization techniques -- that avoids this undesirable behavior, resulting in no misspecification amplification while still obtaining optimal statistical rates. As applications, we use this regression procedure to obtain new guarantees in offline and online reinforcement learning with misspecification and establish new separations between previously studied structural conditions and notions of coverage.