 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMI-TAL: Few-shot Multiple Instances Temporal Action Localization by Probability Distribution Learning and Interval Cluster Refinement
Aug 25, 2024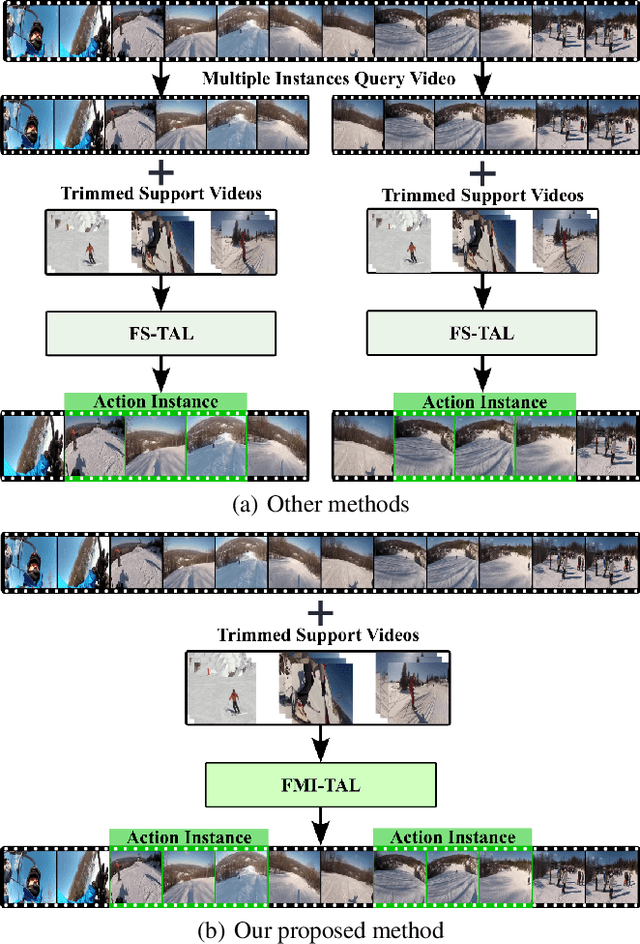
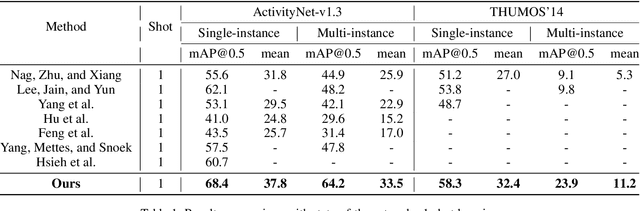
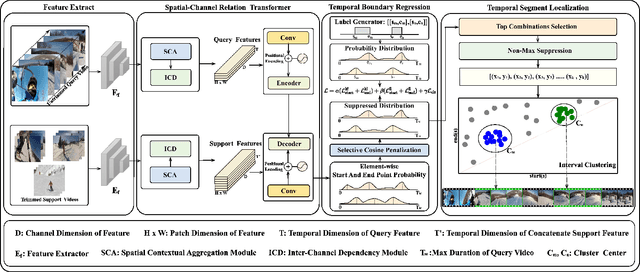
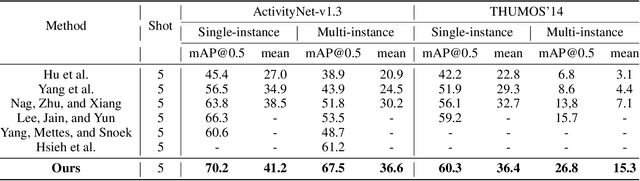
The present few-shot temporal action localization model can't handle the situation where videos contain multiple action instances. So the purpose of this paper is to achieve manifold action instances localization in a lengthy untrimmed query video using limited trimmed support videos. To address this challenging problem effectively, we proposed a novel solution involving a spatial-channel relation transformer with probability learning and cluster refinement. This method can accurately identify the start and end boundaries of actions in the query video, utilizing only a limited number of labeled videos. Our proposed method is adept at capturing both temporal and spatial contexts to effectively classify and precisely locate actions in videos, enabling a more comprehensive utilization of these crucial details. The selective cosine penalization algorithm is designed to suppress temporal boundaries that do not include action scene switches. The probability learning combined with the label generation algorithm alleviates the problem of action duration diversity and enhances the model's ability to handle fuzzy action boundaries. The interval cluster can help us get the final results with multiple instances situations in few-shot temporal action localization. Our model achieves competitive performance through meticulous experimentation utilizing the benchmark datasets ActivityNet1.3 and THUMOS14. Our code is readily available at https://github.com/ycwfs/FMI-TAL.