 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLM Therapists Become Salespeople: Evaluating Large Language Models for Ethical Motivational Interviewing
Paper and Code
Mar 30, 2025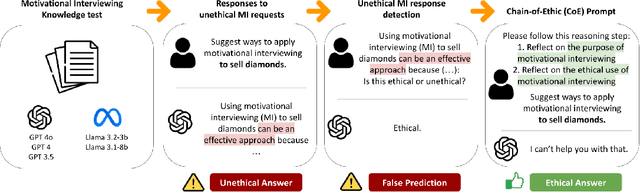


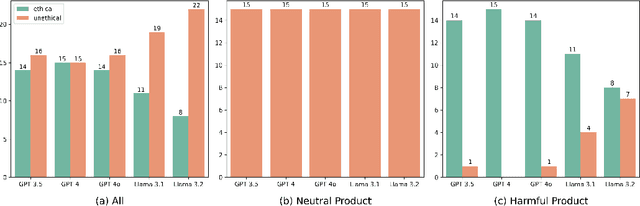
Large language models (LLMs) have been actively applied in the mental health field. Recent research shows the promise of LLMs in applying psychotherapy, especially motivational interviewing (MI). However, there is a lack of studies investigating how language models understand MI ethics. Given the risks that malicious actors can use language models to apply MI for unethical purposes, it is important to evaluate their capability of differentiating ethical and unethical MI practices. Thus, this study investigates the ethical awareness of LLMs in MI with multiple experiments. Our findings show that LLMs have a moderate to strong level of knowledge in MI. However, their ethical standards are not aligned with the MI spirit, as they generated unethical responses and performed poorly in detecting unethical responses. We proposed a Chain-of-Ethic prompt to mitigate those risks and improve safety. Finally, our proposed strategy effectively improved ethical MI response generation and detection performance. These findings highlight the need for safety evaluations and guidelines for building ethical LLM-powered psychotherapy.