 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping
Dec 15, 2024



Video face swapping is becoming increasingly popular across various applications, yet existing methods primarily focus on static images and struggle with video face swapping because of temporal consistency and complex scenarios. In this paper, we present the first diffusion-based framework specifically designed for video face swapping. Our approach introduces a novel image-video hybrid training framework that leverages both abundant static image data and temporal video sequences, addressing the inherent limitations of video-only training. The framework incorporates a specially designed diffusion model coupled with a VidFaceVAE that effectively processes both types of data to better maintain temporal coherence of the generated videos. To further disentangle identity and pose features, we construct the Attribute-Identity Disentanglement Triplet (AIDT) Dataset, where each triplet has three face images, with two images sharing the same pose and two sharing the same identity. Enhanced with a comprehensive occlusion augmentation, this dataset also improves robustness against occlusions. Additionally, we integrate 3D reconstruction techniques as input conditioning to our network for handling large pose variations. Extensive experiments demonstrate that our framework achieves superior performance in identity preservation, temporal consistency, and visual quality compared to existing methods, while requiring fewer inference steps. Our approach effectively mitigates key challenges in video face swapping, including temporal flickering, identity preservation, and robustness to occlusions and pose variations.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021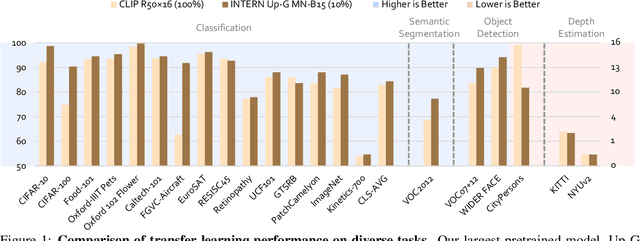
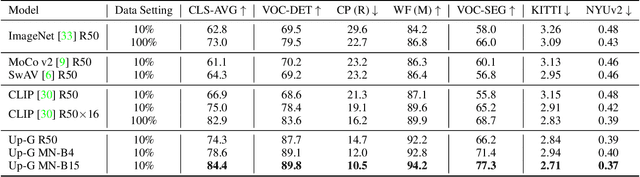
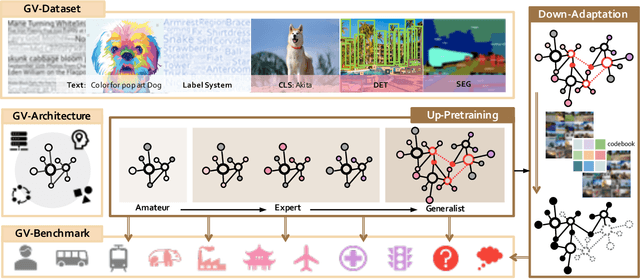
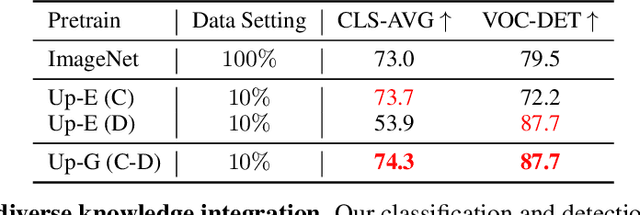
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
DuBox: No-Prior Box Objection Detection via Residual Dual Scale Detectors
Apr 16, 2019

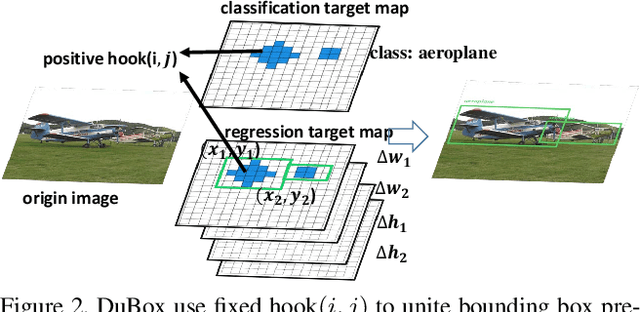
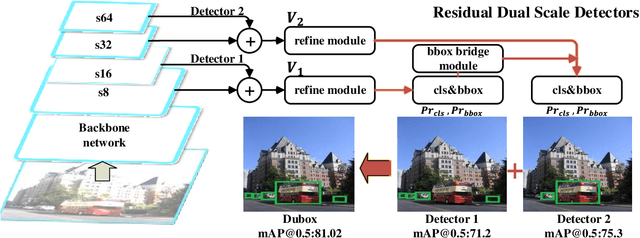
Traditional neural objection detection methods use multi-scale features that allow multiple detectors to perform detecting tasks independently and in parallel. At the same time, with the handling of the prior box, the algorithm's ability to deal with scale invariance is enhanced. However, too many prior boxes and independent detectors will increase the computational redundancy of the detection algorithm. In this study, we introduce Dubox, a new one-stage approach that detects the objects without prior box. Working with multi-scale features, the designed dual scale residual unit makes dual scale detectors no longer run independently. The second scale detector learns the residual of the first. Dubox has enhanced the capacity of heuristic-guided that can further enable the first scale detector to maximize the detection of small targets and the second to detect objects that cannot be identified by the first one. Besides, for each scale detector, with the new classification-regression progressive strapped loss makes our process not based on prior boxes. Integrating these strategies, our detection algorithm has achieved excellent performance in terms of speed and accuracy. Extensive experiments on the VOC, COCO object detection benchmark have confirmed the effectiveness of this algorithm.