 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Development of an Anomaly Detection Interface on the Mars Perseverance Rover using the ISHMAP Framework
Feb 14, 2023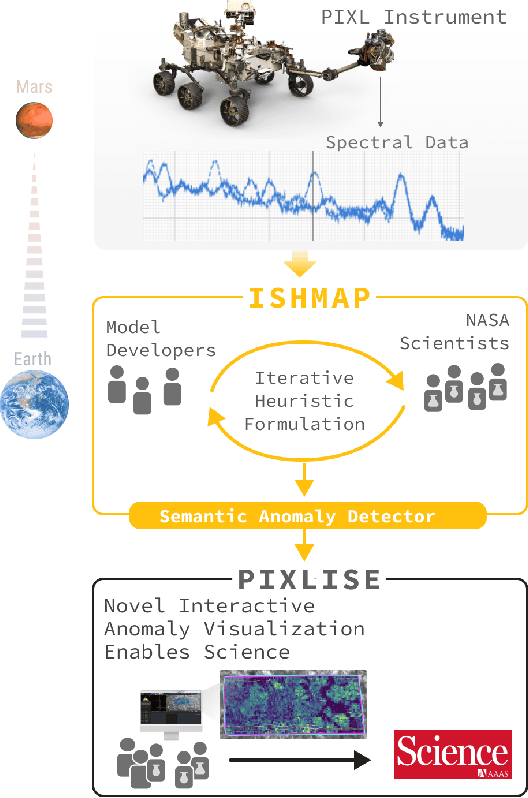
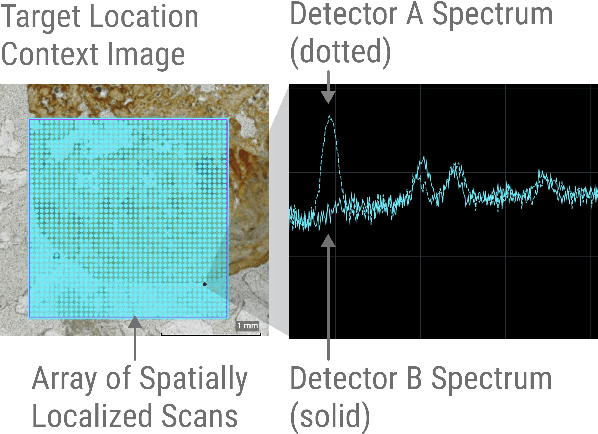
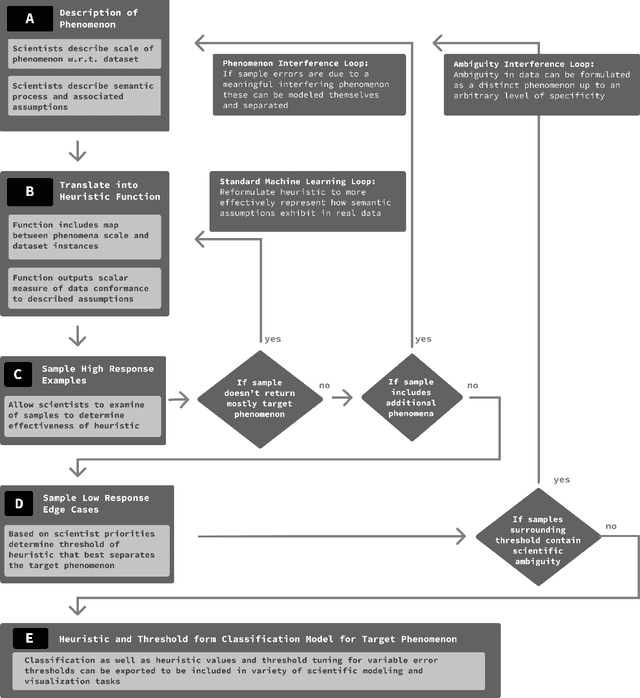
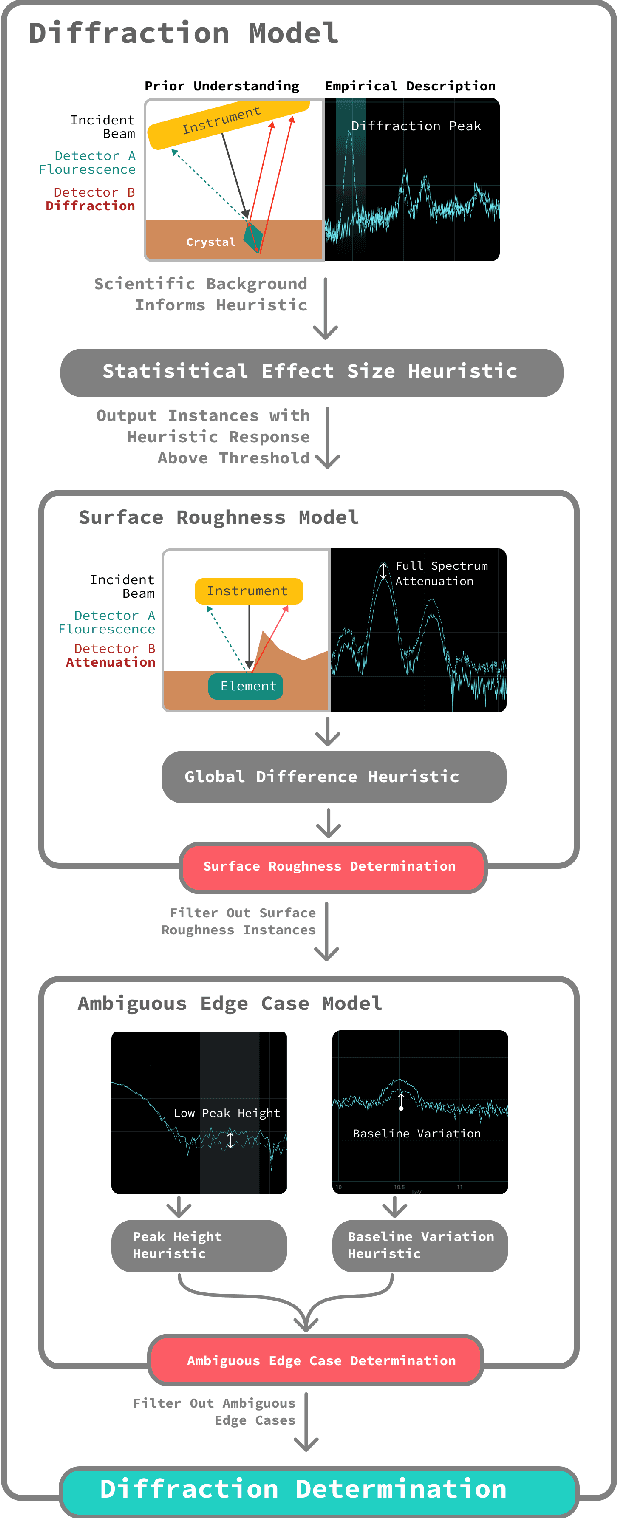
While anomaly detection stands among the most important and valuable problems across many scientific domains, anomaly detection research often focuses on AI methods that can lack the nuance and interpretability so critical to conducting scientific inquiry. In this application paper we present the results of utilizing an alternative approach that situates the mathematical framing of machine learning based anomaly detection within a participatory design framework. In a collaboration with NASA scientists working with the PIXL instrument studying Martian planetary geochemistry as a part of the search for extra-terrestrial life; we report on over 18 months of in-context user research and co-design to define the key problems NASA scientists face when looking to detect and interpret spectral anomalies. We address these problems and develop a novel spectral anomaly detection toolkit for PIXL scientists that is highly accurate while maintaining strong transparency to scientific interpretation. We also describe outcomes from a yearlong field deployment of the algorithm and associated interface. Finally we introduce a new design framework which we developed through the course of this collaboration for co-creating anomaly detection algorithms: Iterative Semantic Heuristic Modeling of Anomalous Phenomena (ISHMAP), which provides a process for scientists and researchers to produce natively interpretable anomaly detection models. This work showcases an example of successfully bridging methodologies from AI and HCI within a scientific domain, and provides a resource in ISHMAP which may be used by other researchers and practitioners looking to partner with other scientific teams to achieve better science through more effective and interpretable anomaly detection tools.
NeuroCartography: Scalable Automatic Visual Summarization of Concepts in Deep Neural Networks
Aug 29, 2021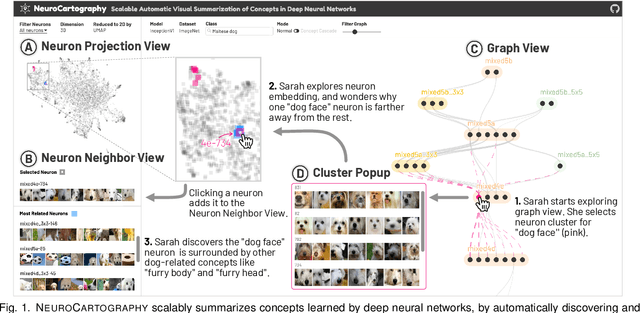


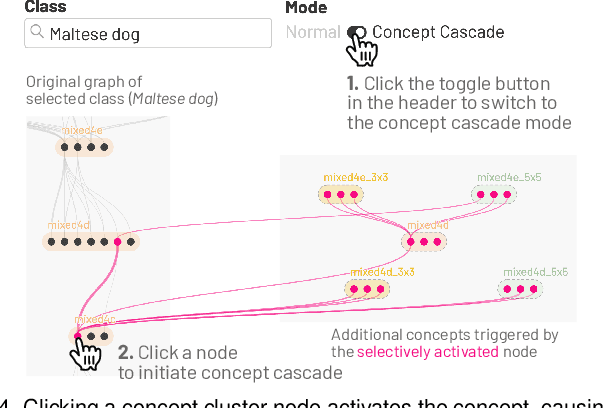
Existing research on making sense of deep neural networks often focuses on neuron-level interpretation, which may not adequately capture the bigger picture of how concepts are collectively encoded by multiple neurons. We present NeuroCartography, an interactive system that scalably summarizes and visualizes concepts learned by neural networks. It automatically discovers and groups neurons that detect the same concepts, and describes how such neuron groups interact to form higher-level concepts and the subsequent predictions. NeuroCartography introduces two scalable summarization techniques: (1) neuron clustering groups neurons based on the semantic similarity of the concepts detected by neurons (e.g., neurons detecting "dog faces" of different breeds are grouped); and (2) neuron embedding encodes the associations between related concepts based on how often they co-occur (e.g., neurons detecting "dog face" and "dog tail" are placed closer in the embedding space). Key to our scalable techniques is the ability to efficiently compute all neuron pairs' relationships, in time linear to the number of neurons instead of quadratic time. NeuroCartography scales to large data, such as the ImageNet dataset with 1.2M images. The system's tightly coordinated views integrate the scalable techniques to visualize the concepts and their relationships, projecting the concept associations to a 2D space in Neuron Projection View, and summarizing neuron clusters and their relationships in Graph View. Through a large-scale human evaluation, we demonstrate that our technique discovers neuron groups that represent coherent, human-meaningful concepts. And through usage scenarios, we describe how our approaches enable interesting and surprising discoveries, such as concept cascades of related and isolated concepts. The NeuroCartography visualization runs in modern browsers and is open-sourced.
Mapping Researchers with PeopleMap
Aug 31, 2020Discovering research expertise at universities can be a difficult task. Directories routinely become outdated, and few help in visually summarizing researchers' work or supporting the exploration of shared interests among researchers. This results in lost opportunities for both internal and external entities to discover new connections, nurture research collaboration, and explore the diversity of research. To address this problem, at Georgia Tech, we have been developing PeopleMap, an open-source interactive web-based tool that uses natural language processing (NLP) to create visual maps for researchers based on their research interests and publications. Requiring only the researchers' Google Scholar profiles as input, PeopleMap generates and visualizes embeddings for the researchers, significantly reducing the need for manual curation of publication information. To encourage and facilitate easy adoption and extension of PeopleMap, we have open-sourced it under the permissive MIT license at https://github.com/poloclub/people-map. PeopleMap has received positive feedback and enthusiasm for expanding its adoption across Georgia Tech.
PeopleMap: Visualization Tool for Mapping Out Researchers using Natural Language Processing
Jun 10, 2020
Discovering research expertise at institutions can be a difficult task. Manually curated university directories easily become out of date and they often lack the information necessary for understanding a researcher's interests and past work, making it harder to explore the diversity of research at an institution and identify research talents. This results in lost opportunities for both internal and external entities to discover new connections and nurture research collaboration. To solve this problem, we have developed PeopleMap, the first interactive, open-source, web-based tool that visually "maps out" researchers based on their research interests and publications by leveraging embeddings generated by natural language processing (NLP) techniques. PeopleMap provides a new engaging way for institutions to summarize their research talents and for people to discover new connections. The platform is developed with ease-of-use and sustainability in mind. Using only researchers' Google Scholar profiles as input, PeopleMap can be readily adopted by any institution using its publicly-accessible repository and detailed documentation.
Comparison of Syntactic and Semantic Representations of Programs in Neural Embeddings
Jan 24, 2020
Neural approaches to program synthesis and understanding have proliferated widely in the last few years; at the same time graph based neural networks have become a promising new tool. This work aims to be the first empirical study comparing the effectiveness of natural language models and static analysis graph based models in representing programs in deep learning systems. It compares graph convolutional networks using different graph representations in the task of program embedding. It shows that the sparsity of control flow graphs and the implicit aggregation of graph convolutional networks cause these models to perform worse than naive models. Therefore it concludes that simply augmenting purely linguistic or statistical models with formal information does not perform well due to the nuanced nature of formal properties introducing more noise than structure for graph convolutional networks.
RECAST: Interactive Auditing of Automatic Toxicity Detection Models
Jan 07, 2020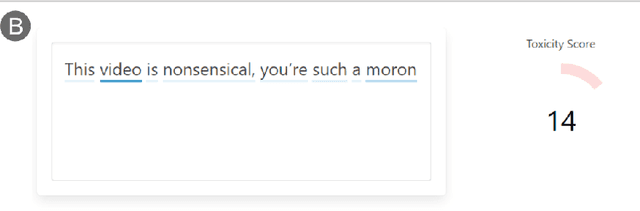
As toxic language becomes nearly pervasive online, there has been increasing interest in leveraging the advancements in natural language processing (NLP), from very large transformer models to automatically detecting and removing toxic comments. Despite the fairness concerns, lack of adversarial robustness, and limited prediction explainability for deep learning systems, there is currently little work for auditing these systems and understanding how they work for both developers and users. We present our ongoing work, RECAST, an interactive tool for examining toxicity detection models by visualizing explanations for predictions and providing alternative wordings for detected toxic speech.