 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Scale Graph Mining for Cyber Threat Intelligence
Nov 09, 2024



Defending against today's increasingly sophisticated and large-scale cyberattacks demands accurate, real-time threat intelligence. Traditional approaches struggle to scale, integrate diverse telemetry, and adapt to a constantly evolving security landscape. We introduce Threat Intelligence Tracking via Adaptive Networks (TITAN), an industry-scale graph mining framework that generates cyber threat intelligence at unprecedented speed and scale. TITAN introduces a suite of innovations specifically designed to address the complexities of the modern security landscape, including: (1) a dynamic threat intelligence graph that maps the intricate relationships between millions of entities, incidents, and organizations; (2) real-time update mechanisms that automatically decay and prune outdated intel; (3) integration of security domain knowledge to bootstrap initial reputation scores; and (4) reputation propagation algorithms that uncover hidden threat actor infrastructure. Integrated into Microsoft Unified Security Operations Platform (USOP), which is deployed across hundreds of thousands of organizations worldwide, TITAN's threat intelligence powers key detection and disruption capabilities. With an impressive average macro-F1 score of 0.89 and a precision-recall AUC of 0.94, TITAN identifies millions of high-risk entities each week, enabling a 6x increase in non-file threat intelligence. Since its deployment, TITAN has increased the product's incident disruption rate by a remarkable 21%, while reducing the time to disrupt by a factor of 1.9x, and maintaining 99% precision, as confirmed by customer feedback and thorough manual evaluation by security experts--ultimately saving customers from costly security breaches.
AI-Driven Guided Response for Security Operation Centers with Microsoft Copilot for Security
Jul 12, 2024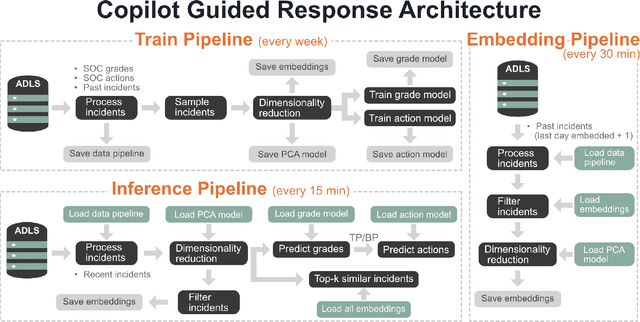
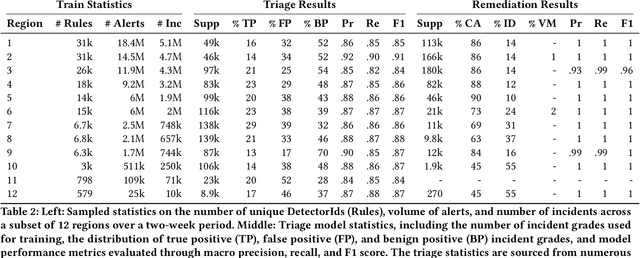
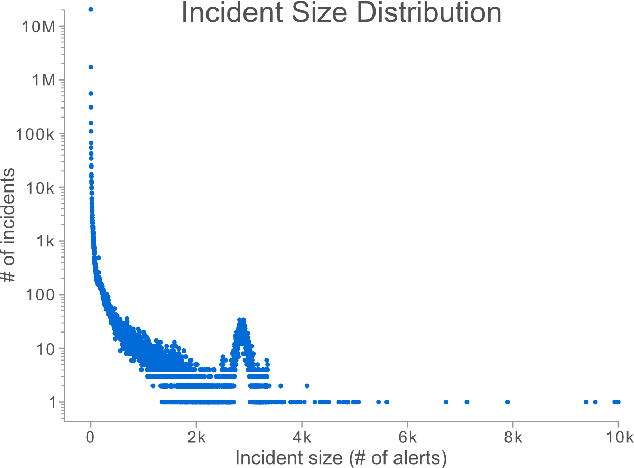
Security operation centers contend with a constant stream of security incidents, ranging from straightforward to highly complex. To address this, we developed Copilot Guided Response (CGR), an industry-scale ML architecture that guides security analysts across three key tasks -- (1) investigation, providing essential historical context by identifying similar incidents; (2) triaging to ascertain the nature of the incident -- whether it is a true positive, false positive, or benign positive; and (3) remediation, recommending tailored containment actions. CGR is integrated into the Microsoft Defender XDR product and deployed worldwide, generating millions of recommendations across thousands of customers. Our extensive evaluation, incorporating internal evaluation, collaboration with security experts, and customer feedback, demonstrates that CGR delivers high-quality recommendations across all three tasks. We provide a comprehensive overview of the CGR architecture, setting a precedent as the first cybersecurity company to openly discuss these capabilities in such depth. Additionally, we GUIDE, the largest public collection of real-world security incidents, spanning 13M evidences across 1M annotated incidents. By enabling researchers and practitioners to conduct research on real-world data, GUIDE advances the state of cybersecurity and supports the development of next-generation machine learning systems.
EnergyVis: Interactively Tracking and Exploring Energy Consumption for ML Models
Mar 30, 2021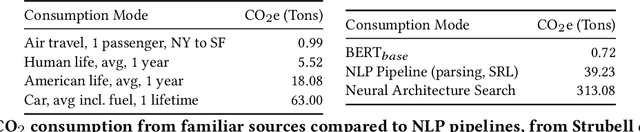
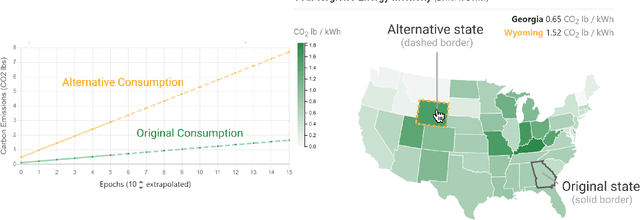
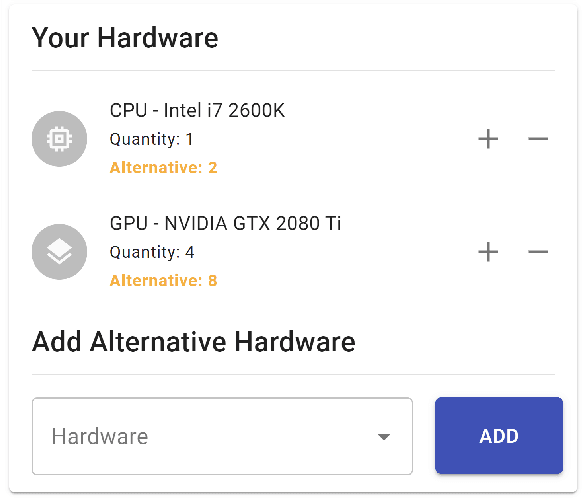
The advent of larger machine learning (ML) models have improved state-of-the-art (SOTA) performance in various modeling tasks, ranging from computer vision to natural language. As ML models continue increasing in size, so does their respective energy consumption and computational requirements. However, the methods for tracking, reporting, and comparing energy consumption remain limited. We presentEnergyVis, an interactive energy consumption tracker for ML models. Consisting of multiple coordinated views, EnergyVis enables researchers to interactively track, visualize and compare model energy consumption across key energy consumption and carbon footprint metrics (kWh and CO2), helping users explore alternative deployment locations and hardware that may reduce carbon footprints. EnergyVis aims to raise awareness concerning computational sustainability by interactively highlighting excessive energy usage during model training; and by providing alternative training options to reduce energy usage.
MalNet: A Large-Scale Cybersecurity Image Database of Malicious Software
Jan 31, 2021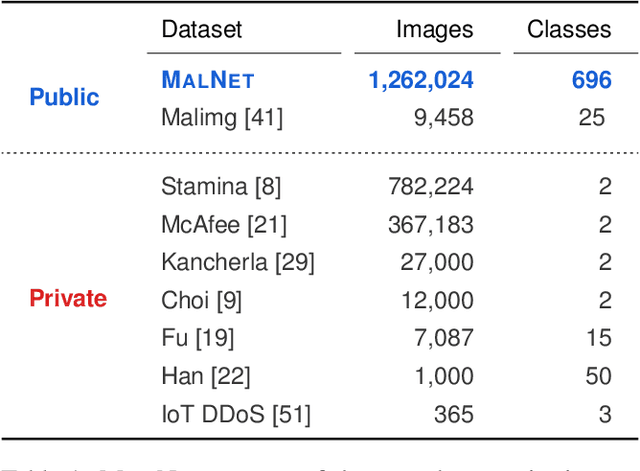
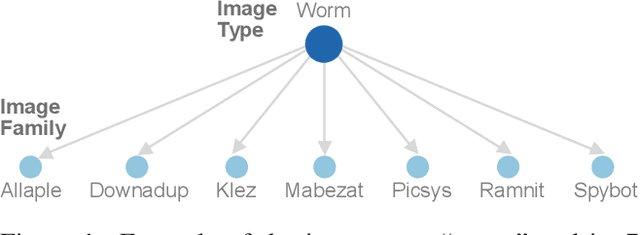
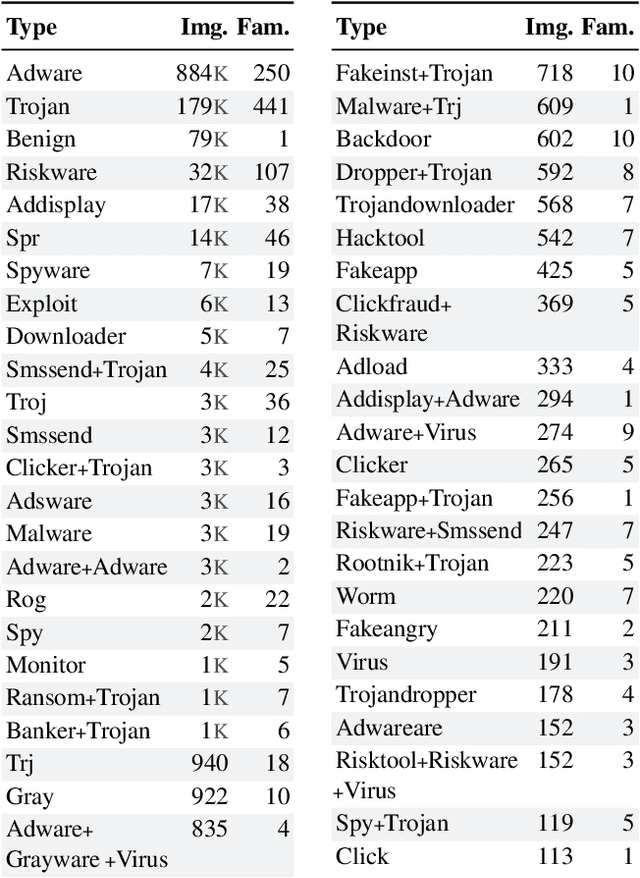
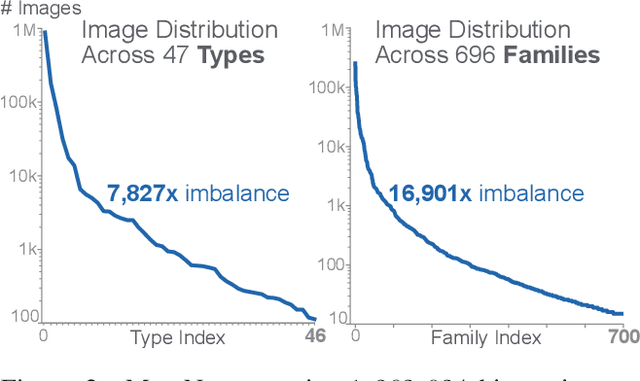
Computer vision is playing an increasingly important role in automated malware detection with to the rise of the image-based binary representation. These binary images are fast to generate, require no feature engineering, and are resilient to popular obfuscation methods. Significant research has been conducted in this area, however, it has been restricted to small-scale or private datasets that only a few industry labs and research teams have access to. This lack of availability hinders examination of existing work, development of new research, and dissemination of ideas. We introduce MalNet, the largest publicly available cybersecurity image database, offering 133x more images and 27x more classes than the only other public binary-image database. MalNet contains over 1.2 million images across a hierarchy of 47 types and 696 families. We provide extensive analysis of MalNet, discussing its properties and provenance. The scale and diversity of MalNet unlocks new and exciting cybersecurity opportunities to the computer vision community--enabling discoveries and research directions that were previously not possible. The database is publicly available at www.mal-net.org.
A Large-Scale Database for Graph Representation Learning
Nov 16, 2020
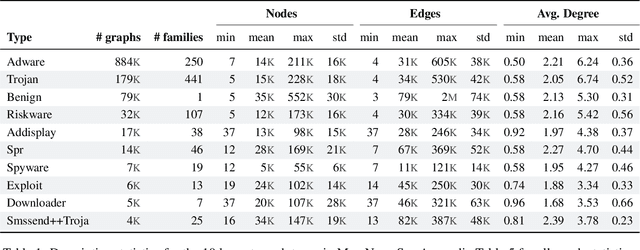
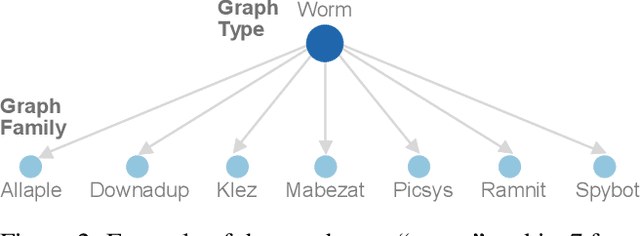

With the rapid emergence of graph representation learning, the construction of new large-scale datasets are necessary to distinguish model capabilities and accurately assess the strengths and weaknesses of each technique. By carefully analyzing existing graph databases, we identify 3 critical components important for advancing the field of graph representation learning: (1) large graphs, (2) many graphs, and (3) class diversity. To date, no single graph database offers all of these desired properties. We introduce MalNet, the largest public graph database ever constructed, representing a large-scale ontology of software function call graphs. MalNet contains over 1.2 million graphs, averaging over 17k nodes and 39k edges per graph, across a hierarchy of 47 types and 696 families. Compared to the popular REDDIT-12K database, MalNet offers 105x more graphs, 44x larger graphs on average, and 63x the classes. We provide a detailed analysis of MalNet, discussing its properties and provenance. The unprecedented scale and diversity of MalNet offers exciting opportunities to advance the frontiers of graph representation learning---enabling new discoveries and research into imbalanced classification, explainability and the impact of class hardness. The database is publically available at www.mal-net.org.
ELF: An Early-Exiting Framework for Long-Tailed Classification
Jun 22, 2020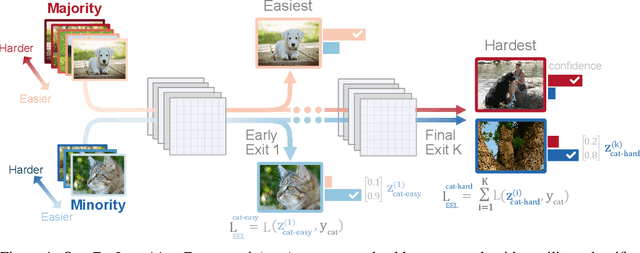
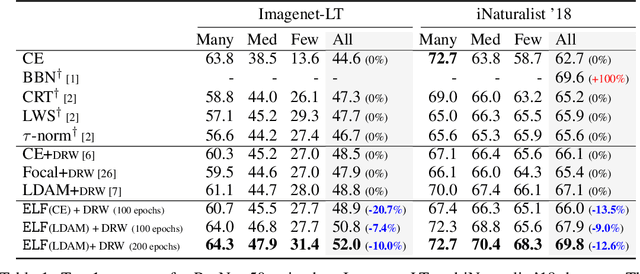

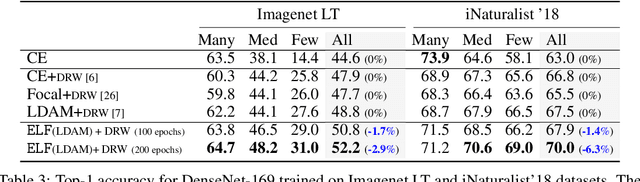
The natural world often follows a long-tailed data distribution where only a few classes account for most of the examples. This long-tail causes classifiers to overfit to the majority class. To mitigate this, prior solutions commonly adopt class rebalancing strategies such as data resampling and loss reshaping. However, by treating each example within a class equally, these methods fail to account for the important notion of example hardness, i.e., within each class some examples are easier to classify than others. To incorporate this notion of hardness into the learning process, we propose the EarLy-exiting Framework(ELF). During training, ELF learns to early-exit easy examples through auxiliary branches attached to a backbone network. This offers a dual benefit-(1) the neural network increasingly focuses on hard examples, since they contribute more to the overall network loss; and (2) it frees up additional model capacity to distinguish difficult examples. Experimental results on two large-scale datasets, ImageNet LT and iNaturalist'18, demonstrate that ELF can improve state-of-the-art accuracy by more than 3 percent. This comes with the additional benefit of reducing up to 20 percent of inference time FLOPS. ELF is complementary to prior work and can naturally integrate with a variety of existing methods to tackle the challenge of long-tailed distributions.
Evaluating Graph Vulnerability and Robustness using TIGER
Jun 10, 2020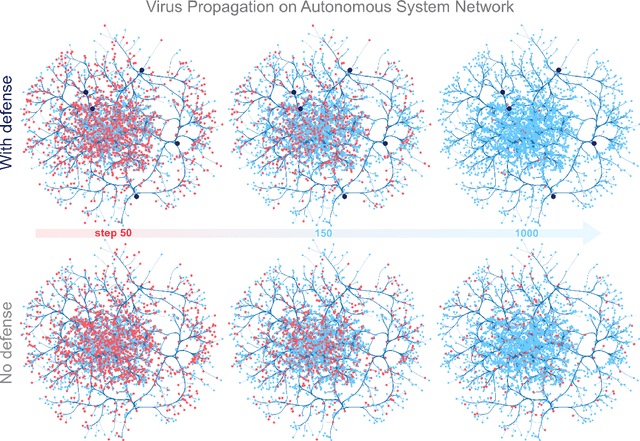
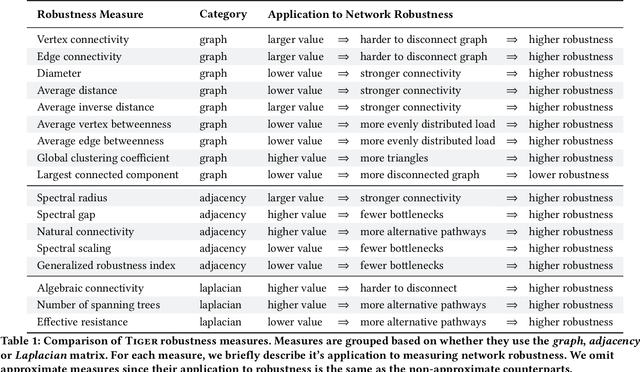
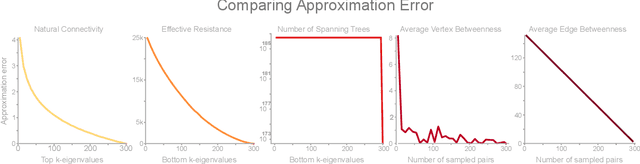
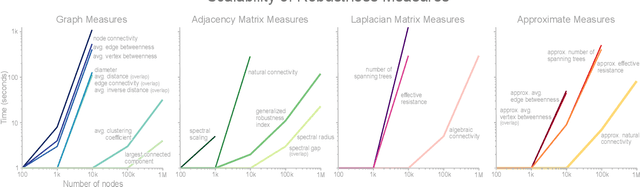
The study of network robustness is a critical tool in the characterization and understanding of complex interconnected systems such as transportation, infrastructure, communication, and computer networks. Through analyzing and understanding the robustness of these networks we can:(1) quantify network vulnerability and robustness,(2) augment a network's structure to resist attacks and recover from failure, and (3) control the dissemination of entities on the network (e.g., viruses, propaganda). While significant research has been conducted on all of these tasks, no comprehensive open-source toolbox currently exists to assist researchers and practitioners in this important topic. This lack of available tools hinders reproducibility and examination of existing work, development of new research, and dissemination of new ideas. We contribute TIGER, an open-sourced Python toolbox to address these challenges. TIGER contains 22 graph robustness measures with both original and fast approximate versions; 17 failure and attack strategies; 15 heuristic and optimization based defense techniques; and 4 simulation tools. By democratizing the tools required to study network robustness, our goal is to assist researchers and practitioners in analyzing their own networks; and facilitate the development of new research in the field. TIGER is open-sourced at: https://github.com/safreita1/TIGER
UnMask: Adversarial Detection and Defense Through Robust Feature Alignment
Feb 21, 2020
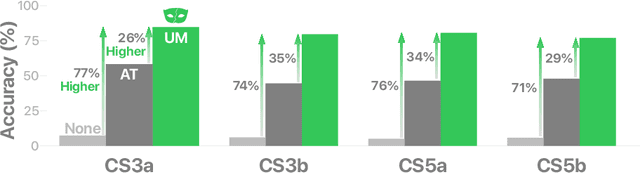
Deep learning models are being integrated into a wide range of high-impact, security-critical systems, from self-driving cars to medical diagnosis. However, recent research has demonstrated that many of these deep learning architectures are vulnerable to adversarial attacks--highlighting the vital need for defensive techniques to detect and mitigate these attacks before they occur. To combat these adversarial attacks, we developed UnMask, an adversarial detection and defense framework based on robust feature alignment. The core idea behind UnMask is to protect these models by verifying that an image's predicted class ("bird") contains the expected robust features (e.g., beak, wings, eyes). For example, if an image is classified as "bird", but the extracted features are wheel, saddle and frame, the model may be under attack. UnMask detects such attacks and defends the model by rectifying the misclassification, re-classifying the image based on its robust features. Our extensive evaluation shows that UnMask (1) detects up to 96.75% of attacks, with a false positive rate of 9.66% and (2) defends the model by correctly classifying up to 93% of adversarial images produced by the current strongest attack, Projected Gradient Descent, in the gray-box setting. UnMask provides significantly better protection than adversarial training across 8 attack vectors, averaging 31.18% higher accuracy. Our proposed method is architecture agnostic and fast. We open source the code repository and data with this paper: https://github.com/unmaskd/unmask.
REST: Robust and Efficient Neural Networks for Sleep Monitoring in the Wild
Jan 29, 2020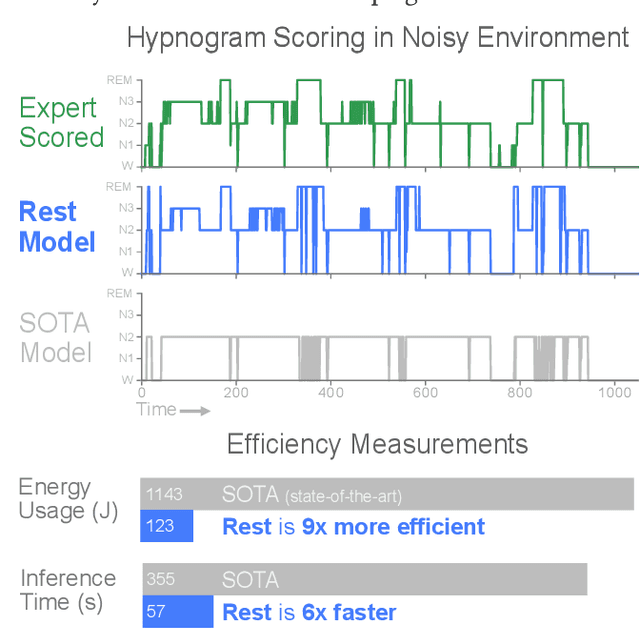
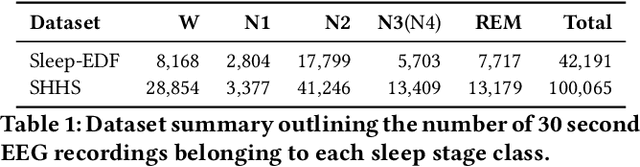
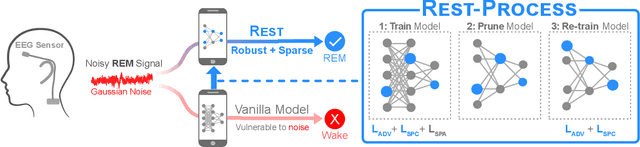
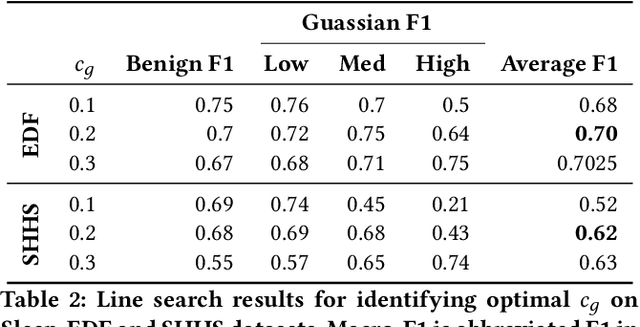
In recent years, significant attention has been devoted towards integrating deep learning technologies in the healthcare domain. However, to safely and practically deploy deep learning models for home health monitoring, two significant challenges must be addressed: the models should be (1) robust against noise; and (2) compact and energy-efficient. We propose REST, a new method that simultaneously tackles both issues via 1) adversarial training and controlling the Lipschitz constant of the neural network through spectral regularization while 2) enabling neural network compression through sparsity regularization. We demonstrate that REST produces highly-robust and efficient models that substantially outperform the original full-sized models in the presence of noise. For the sleep staging task over single-channel electroencephalogram (EEG), the REST model achieves a macro-F1 score of 0.67 vs. 0.39 achieved by a state-of-the-art model in the presence of Gaussian noise while obtaining 19x parameter reduction and 15x MFLOPS reduction on two large, real-world EEG datasets. By deploying these models to an Android application on a smartphone, we quantitatively observe that REST allows models to achieve up to 17x energy reduction and 9x faster inference. We open-source the code repository with this paper: https://github.com/duggalrahul/REST.