Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation in Embedded Spaces
Paper and Code
Mar 05, 2022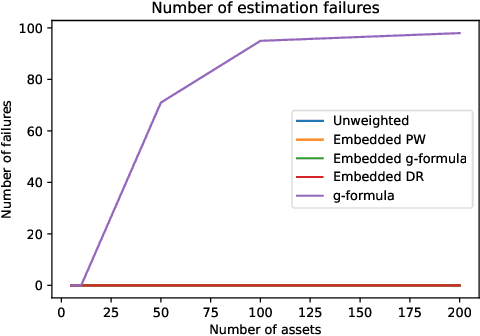
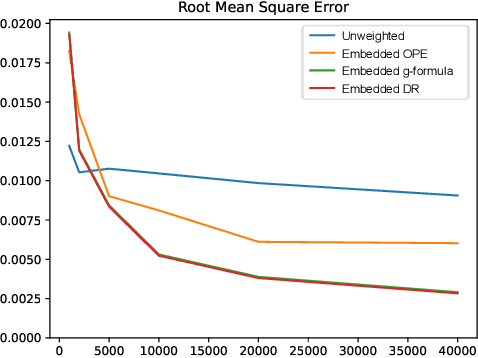
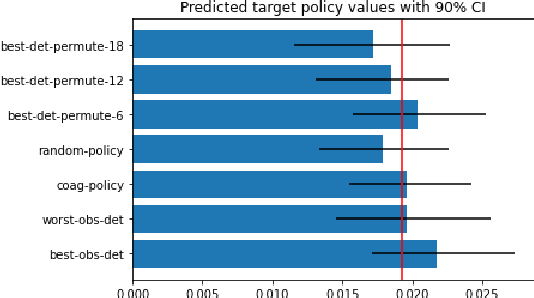
Off-policy evaluation methods are important in recommendation systems and search engines, whereby data collected under an old logging policy is used to predict the performance of a new target policy. However, in practice most systems are not observed to recommend most of the possible actions, which is an issue since existing methods require that the probability of the target policy recommending an item can only be non-zero when the probability of the logging policy is non-zero (known as absolute continuity). To circumvent this issue, we explore the use of action embeddings. By representing contexts and actions in an embedding space, we are able to share information to extrapolate behaviors for actions and contexts previously unseen.
* 9 pages, appeared at NeurIPS 2021 Workshop "Causal Inference
Challenges in Sequential Decision Making: Bridging Theory and Practice",
presented virtually Dec 14th 2021
View paper on