 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-adaptive model selection over a collection of black-box contextual bandit algorithms
Paper and Code
Jun 05, 2020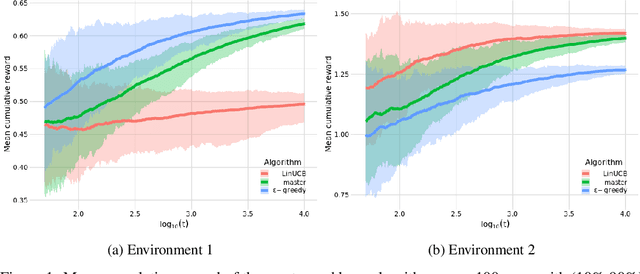
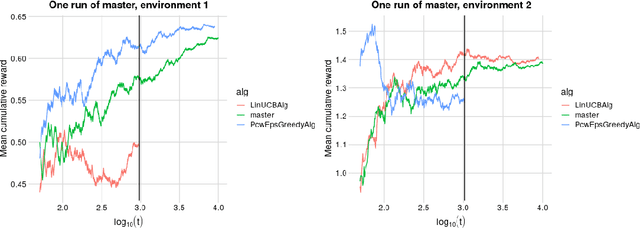
We consider the model selection task in the stochastic contextual bandit setting. Suppose we are given a collection of base contextual bandit algorithms. We provide a master algorithm that combines them and achieves the same performance, up to constants, as the best base algorithm would, if it had been run on its own. Our approach only requires that each algorithm satisfy a high probability regret bound. Our procedure is very simple and essentially does the following: for a well chosen sequence of probabilities $(p_{t})_{t\geq 1}$, at each round $t$, it either chooses at random which candidate to follow (with probability $p_{t}$) or compares, at the same internal sample size for each candidate, the cumulative reward of each, and selects the one that wins the comparison (with probability $1-p_{t}$). To the best of our knowledge, our proposal is the first one to be rate-adaptive for a collection of general black-box contextual bandit algorithms: it achieves the same regret rate as the best candidate. We demonstrate the effectiveness of our method with simulation studies.