 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalized Fair Regression for Multiple Groups in Chronic Kidney Disease
Dec 19, 2025



Fair regression methods have the potential to mitigate societal bias concerns in health care, but there has been little work on penalized fair regression when multiple groups experience such bias. We propose a general regression framework that addresses this gap with unfairness penalties for multiple groups. Our approach is demonstrated for binary outcomes with true positive rate disparity penalties. It can be efficiently implemented through reduction to a cost-sensitive classification problem. We additionally introduce novel score functions for automatically selecting penalty weights. Our penalized fair regression methods are empirically studied in simulations, where they achieve a fairness-accuracy frontier beyond that of existing comparison methods. Finally, we apply these methods to a national multi-site primary care study of chronic kidney disease to develop a fair classifier for end-stage renal disease. There we find substantial improvements in fairness for multiple race and ethnicity groups who experience societal bias in the health care system without any appreciable loss in overall fit.
Capturing Actionable Dynamics with Structured Latent Ordinary Differential Equations
Feb 25, 2022



End-to-end learning of dynamical systems with black-box models, such as neural ordinary differential equations (ODEs), provides a flexible framework for learning dynamics from data without prescribing a mathematical model for the dynamics. Unfortunately, this flexibility comes at the cost of understanding the dynamical system, for which ODEs are used ubiquitously. Further, experimental data are collected under various conditions (inputs), such as treatments, or grouped in some way, such as part of sub-populations. Understanding the effects of these system inputs on system outputs is crucial to have any meaningful model of a dynamical system. To that end, we propose a structured latent ODE model that explicitly captures system input variations within its latent representation. Building on a static latent variable specification, our model learns (independent) stochastic factors of variation for each input to the system, thus separating the effects of the system inputs in the latent space. This approach provides actionable modeling through the controlled generation of time-series data for novel input combinations (or perturbations). Additionally, we propose a flexible approach for quantifying uncertainties, leveraging a quantile regression formulation. Experimental results on challenging biological datasets show consistent improvements over competitive baselines in the controlled generation of observational data and prediction of biologically meaningful system inputs.
Why Machine Learning Cannot Ignore Maximum Likelihood Estimation
Oct 23, 2021The growth of machine learning as a field has been accelerating with increasing interest and publications across fields, including statistics, but predominantly in computer science. How can we parse this vast literature for developments that exemplify the necessary rigor? How many of these manuscripts incorporate foundational theory to allow for statistical inference? Which advances have the greatest potential for impact in practice? One could posit many answers to these queries. Here, we assert that one essential idea is for machine learning to integrate maximum likelihood for estimation of functional parameters, such as prediction functions and conditional densities.
Conditional Cross-Design Synthesis Estimators for Generalizability in Medicaid
Sep 27, 2021While much of the causal inference literature has focused on addressing internal validity biases, both internal and external validity are necessary for unbiased estimates in a target population of interest. However, few generalizability approaches exist for estimating causal quantities in a target population when the target population is not well-represented by a randomized study but is reflected when additionally incorporating observational data. To generalize to a target population represented by a union of these data, we propose a class of novel conditional cross-design synthesis estimators that combine randomized and observational data, while addressing their respective biases. The estimators include outcome regression, propensity weighting, and double robust approaches. All use the covariate overlap between the randomized and observational data to remove potential unmeasured confounding bias. We apply these methods to estimate the causal effect of managed care plans on health care spending among Medicaid beneficiaries in New York City.
Considerations Across Three Cultures: Parametric Regressions, Interpretable Algorithms, and Complex Algorithms
Apr 14, 2021We consider an extension of Leo Breiman's thesis from "Statistical Modeling: The Two Cultures" to include a bifurcation of algorithmic modeling, focusing on parametric regressions, interpretable algorithms, and complex (possibly explainable) algorithms.
A Review of Generalizability and Transportability
Feb 23, 2021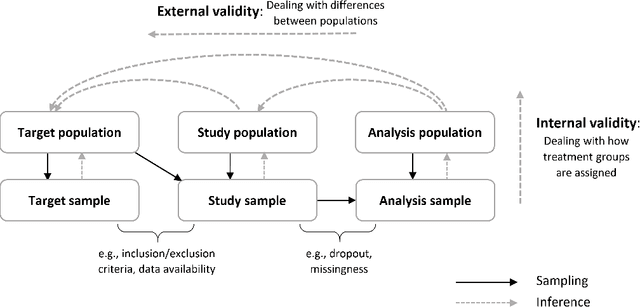

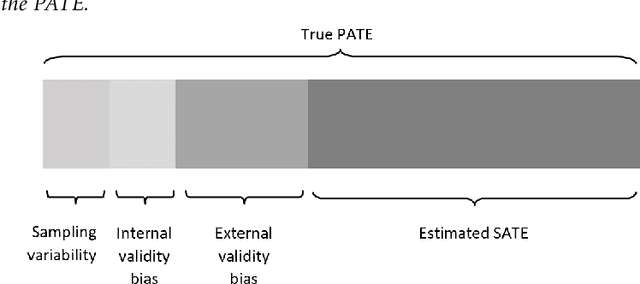
When assessing causal effects, determining the target population to which the results are intended to generalize is a critical decision. Randomized and observational studies each have strengths and limitations for estimating causal effects in a target population. Estimates from randomized data may have internal validity but are often not representative of the target population. Observational data may better reflect the target population, and hence be more likely to have external validity, but are subject to potential bias due to unmeasured confounding. While much of the causal inference literature has focused on addressing internal validity bias, both internal and external validity are necessary for unbiased estimates in a target population. This paper presents a framework for addressing external validity bias, including a synthesis of approaches for generalizability and transportability, the assumptions they require, as well as tests for the heterogeneity of treatment effects and differences between study and target populations.
Ethical Machine Learning in Health Care
Oct 08, 2020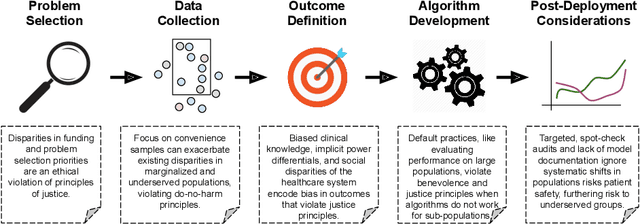
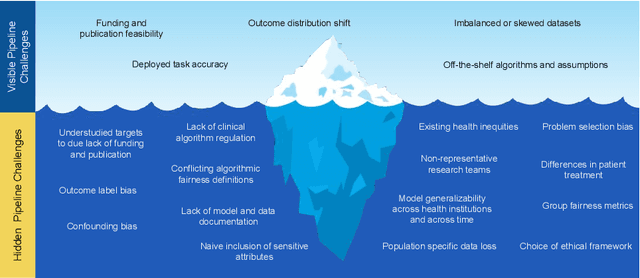
The use of machine learning (ML) in health care raises numerous ethical concerns, especially as models can amplify existing health inequities. Here, we outline ethical considerations for equitable ML in the advancement of health care. Specifically, we frame ethics of ML in health care through the lens of social justice. We describe ongoing efforts and outline challenges in a proposed pipeline of ethical ML in health, ranging from problem selection to post-deployment considerations. We close by summarizing recommendations to address these challenges.
Fair Regression for Health Care Spending
Jan 28, 2019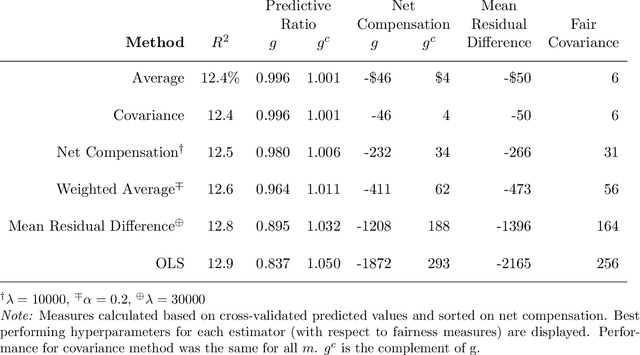
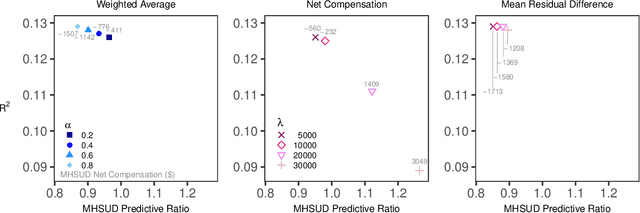
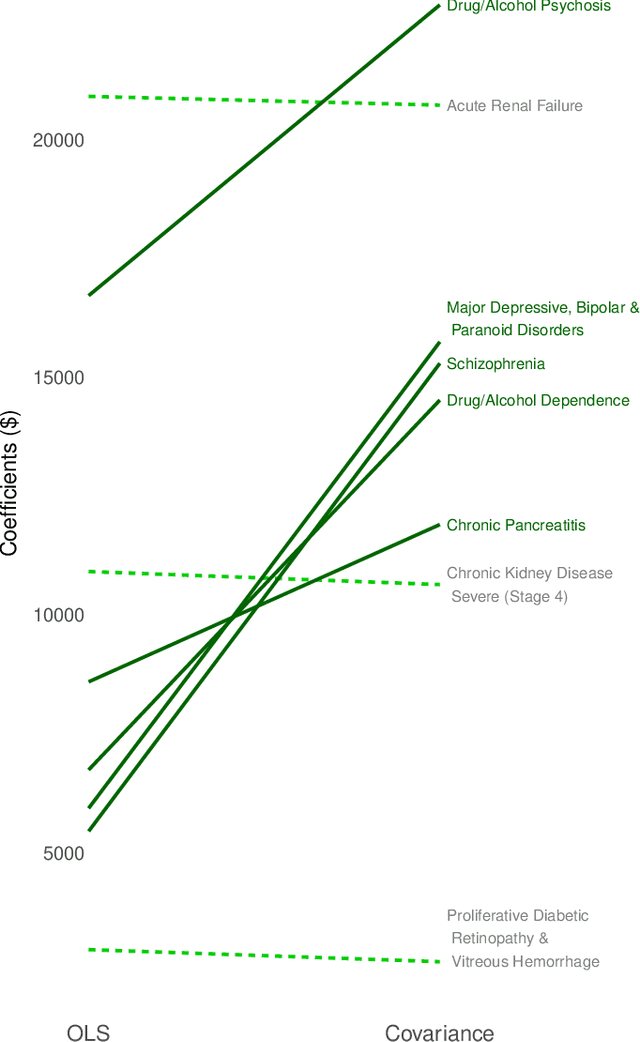
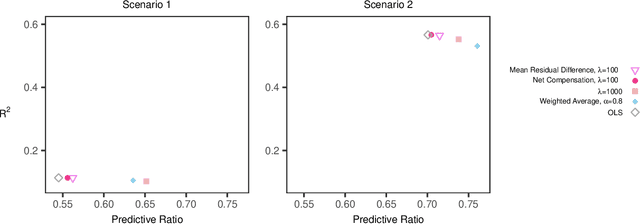
The distribution of health care payments to insurance plans has substantial consequences for social policy. Risk adjustment formulas predict spending in health insurance markets in order to provide fair benefits and health care coverage for all enrollees, regardless of their health status. Unfortunately, current risk adjustment formulas are known to undercompensate payments to health insurers for specific groups of enrollees (by underpredicting their spending). Much of the existing algorithmic fairness literature for group fairness to date has focused on classifiers and binary outcomes. To improve risk adjustment formulas for undercompensated groups, we expand on concepts from the statistics, computer science, and health economics literature to develop new fair regression methods for continuous outcomes by building fairness considerations directly into the objective function. We additionally propose a novel measure of fairness while asserting that a suite of metrics is necessary in order to evaluate risk adjustment formulas more fully. Our data application using the IBM MarketScan Research Databases and simulation studies demonstrate that these new fair regression methods may lead to massive improvements in group fairness with only small reductions in overall fit.
Stacked Propensity Score Functions for Observational Cohorts with Oversampled Exposed Subjects
May 20, 2018



Observational cohort studies with oversampled exposed subjects are typically implemented to understand the causal effect of a rare exposure. Because the distribution of exposed subjects in the sample differs from the source population, estimation of a propensity score function (i.e., probability of exposure given baseline covariates) targets a nonparametrically nonidentifiable parameter. Consistent estimation of propensity score functions is an important component of various causal inference estimators, including double robust machine learning and inverse probability weighted estimators. We propose the use of the probability of exposure from the source population in observation-weighted stacking algorithms to produce consistent estimators of propensity score functions. Simulation studies and a hypothetical health policy intervention data analysis demonstrate low empirical bias and variance for these stacked propensity score functions with observation weights.