 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of the conditional exchangeability assumption in causal machine learning models: a simulation study
Oct 30, 2025Observational studies developing causal machine learning (ML) models for the prediction of individualized treatment effects (ITEs) seldom conduct empirical evaluations to assess the conditional exchangeability assumption. We aimed to evaluate the performance of these models under conditional exchangeability violations and the utility of negative control outcomes (NCOs) as a diagnostic. We conducted a simulation study to examine confounding bias in ITE estimates generated by causal forest and X-learner models under varying conditions, including the presence or absence of true heterogeneity. We simulated data to reflect real-world scenarios with differing levels of confounding, sample size, and NCO confounding structures. We then estimated and compared subgroup-level treatment effects on the primary outcome and NCOs across settings with and without unmeasured confounding. When conditional exchangeability was violated, causal forest and X-learner models failed to recover true treatment effect heterogeneity and, in some cases, falsely indicated heterogeneity when there was none. NCOs successfully identified subgroups affected by unmeasured confounding. Even when NCOs did not perfectly satisfy its ideal assumptions, it remained informative, flagging potential bias in subgroup level estimates, though not always pinpointing the subgroup with the largest confounding. Violations of conditional exchangeability substantially limit the validity of ITE estimates from causal ML models in routinely collected observational data. NCOs serve a useful empirical diagnostic tool for detecting subgroup-specific unmeasured confounding and should be incorporated into causal ML workflows to support the credibility of individualized inference.
BRIDGE: Benchmarking Large Language Models for Understanding Real-world Clinical Practice Text
May 01, 2025



Large language models (LLMs) hold great promise for medical applications and are evolving rapidly, with new models being released at an accelerated pace. However, current evaluations of LLMs in clinical contexts remain limited. Most existing benchmarks rely on medical exam-style questions or PubMed-derived text, failing to capture the complexity of real-world electronic health record (EHR) data. Others focus narrowly on specific application scenarios, limiting their generalizability across broader clinical use. To address this gap, we present BRIDGE, a comprehensive multilingual benchmark comprising 87 tasks sourced from real-world clinical data sources across nine languages. We systematically evaluated 52 state-of-the-art LLMs (including DeepSeek-R1, GPT-4o, Gemini, and Llama 4) under various inference strategies. With a total of 13,572 experiments, our results reveal substantial performance variation across model sizes, languages, natural language processing tasks, and clinical specialties. Notably, we demonstrate that open-source LLMs can achieve performance comparable to proprietary models, while medically fine-tuned LLMs based on older architectures often underperform versus updated general-purpose models. The BRIDGE and its corresponding leaderboard serve as a foundational resource and a unique reference for the development and evaluation of new LLMs in real-world clinical text understanding. The BRIDGE leaderboard: https://huggingface.co/spaces/YLab-Open/BRIDGE-Medical-Leaderboard
High-dimensional multiple imputation (HDMI) for partially observed confounders including natural language processing-derived auxiliary covariates
May 17, 2024Multiple imputation (MI) models can be improved by including auxiliary covariates (AC), but their performance in high-dimensional data is not well understood. We aimed to develop and compare high-dimensional MI (HDMI) approaches using structured and natural language processing (NLP)-derived AC in studies with partially observed confounders. We conducted a plasmode simulation study using data from opioid vs. non-steroidal anti-inflammatory drug (NSAID) initiators (X) with observed serum creatinine labs (Z2) and time-to-acute kidney injury as outcome. We simulated 100 cohorts with a null treatment effect, including X, Z2, atrial fibrillation (U), and 13 other investigator-derived confounders (Z1) in the outcome generation. We then imposed missingness (MZ2) on 50% of Z2 measurements as a function of Z2 and U and created different HDMI candidate AC using structured and NLP-derived features. We mimicked scenarios where U was unobserved by omitting it from all AC candidate sets. Using LASSO, we data-adaptively selected HDMI covariates associated with Z2 and MZ2 for MI, and with U to include in propensity score models. The treatment effect was estimated following propensity score matching in MI datasets and we benchmarked HDMI approaches against a baseline imputation and complete case analysis with Z1 only. HDMI using claims data showed the lowest bias (0.072). Combining claims and sentence embeddings led to an improvement in the efficiency displaying the lowest root-mean-squared-error (0.173) and coverage (94%). NLP-derived AC alone did not perform better than baseline MI. HDMI approaches may decrease bias in studies with partially observed confounders where missingness depends on unobserved factors.
Collaborative-controlled LASSO for Constructing Propensity Score-based Estimators in High-Dimensional Data
Jun 30, 2017
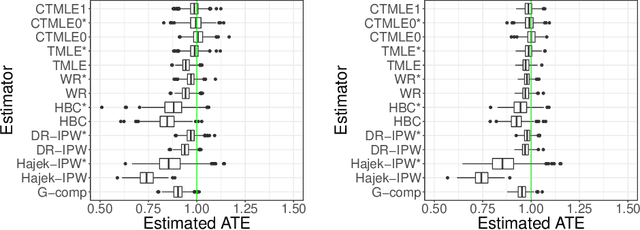
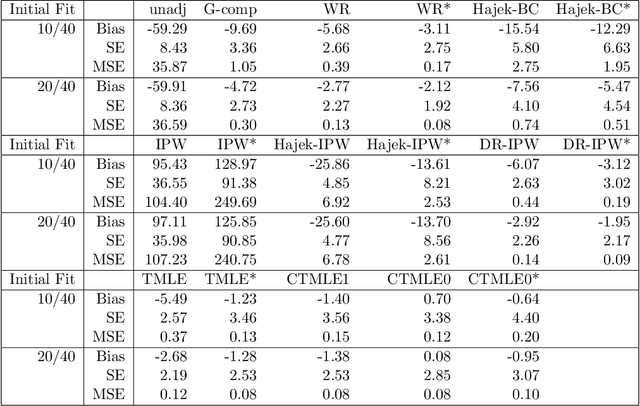
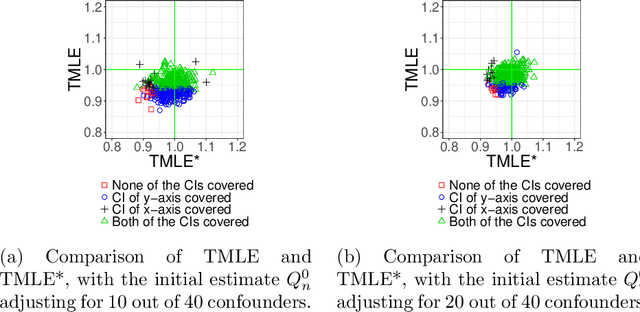
Propensity score (PS) based estimators are increasingly used for causal inference in observational studies. However, model selection for PS estimation in high-dimensional data has received little attention. In these settings, PS models have traditionally been selected based on the goodness-of-fit for the treatment mechanism itself, without consideration of the causal parameter of interest. Collaborative minimum loss-based estimation (C-TMLE) is a novel methodology for causal inference that takes into account information on the causal parameter of interest when selecting a PS model. This "collaborative learning" considers variable associations with both treatment and outcome when selecting a PS model in order to minimize a bias-variance trade off in the estimated treatment effect. In this study, we introduce a novel approach for collaborative model selection when using the LASSO estimator for PS estimation in high-dimensional covariate settings. To demonstrate the importance of selecting the PS model collaboratively, we designed quasi-experiments based on a real electronic healthcare database, where only the potential outcomes were manually generated, and the treatment and baseline covariates remained unchanged. Results showed that the C-TMLE algorithm outperformed other competing estimators for both point estimation and confidence interval coverage. In addition, the PS model selected by C-TMLE could be applied to other PS-based estimators, which also resulted in substantive improvement for both point estimation and confidence interval coverage. We illustrate the discussed concepts through an empirical example comparing the effects of non-selective nonsteroidal anti-inflammatory drugs with selective COX-2 inhibitors on gastrointestinal complications in a population of Medicare beneficiaries.
Propensity score prediction for electronic healthcare databases using Super Learner and High-dimensional Propensity Score Methods
Mar 14, 2017

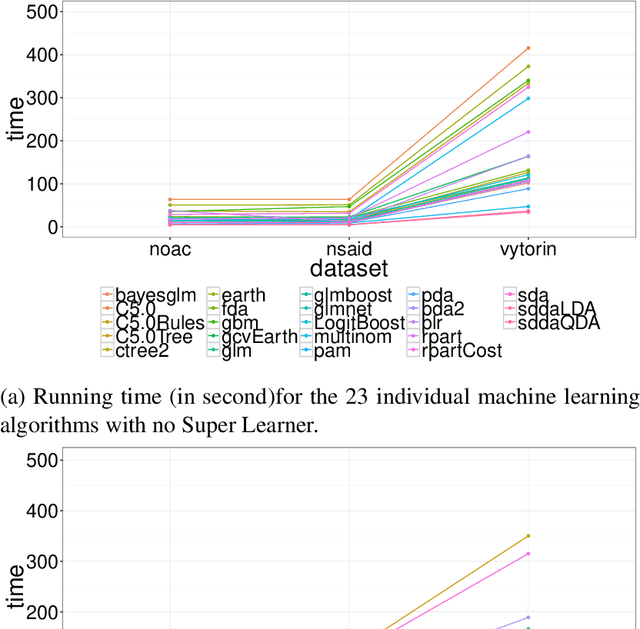

The optimal learner for prediction modeling varies depending on the underlying data-generating distribution. Super Learner (SL) is a generic ensemble learning algorithm that uses cross-validation to select among a "library" of candidate prediction models. The SL is not restricted to a single prediction model, but uses the strengths of a variety of learning algorithms to adapt to different databases. While the SL has been shown to perform well in a number of settings, it has not been thoroughly evaluated in large electronic healthcare databases that are common in pharmacoepidemiology and comparative effectiveness research. In this study, we applied and evaluated the performance of the SL in its ability to predict treatment assignment using three electronic healthcare databases. We considered a library of algorithms that consisted of both nonparametric and parametric models. We also considered a novel strategy for prediction modeling that combines the SL with the high-dimensional propensity score (hdPS) variable selection algorithm. Predictive performance was assessed using three metrics: the negative log-likelihood, area under the curve (AUC), and time complexity. Results showed that the best individual algorithm, in terms of predictive performance, varied across datasets. The SL was able to adapt to the given dataset and optimize predictive performance relative to any individual learner. Combining the SL with the hdPS was the most consistent prediction method and may be promising for PS estimation and prediction modeling in electronic healthcare databases.