 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Agreement Consistency Learning for Semi-Supervised Fetal Ultrasound Segmentation
Jun 24, 2026Maternal-fetal US is the primary imaging modality for monitoring fetal development, yet accurate automated segmentation remains challenging due to the scarcity of pixel-level annotations. To address this issue, we propose DACL, a semi-supervised framework for robust fetal US image segmentation. DACL jointly trains a deployment-oriented lightweight convolutional network (1.47\thinsp\mathrm{M} parameters) and a Transformer-based network, leveraging labeled data for supervised learning and unlabeled data via CPS. To enhance prediction stability, we introduce a dual-agreement consistency loss that couples pixel-wise probabilistic divergence with entropy-guided confidence alignment. Unlike conventional CPS methods that enforce agreement only at the prediction level, DACL explicitly regularizes both distributional alignment and uncertainty, thereby suppressing unreliable pseudo-labels and enabling stable cross-architecture pseudo-label learning under extreme annotation scarcity. Furthermore, an interpolation-based consistency strategy using mixup is applied to unlabeled samples to enhance robustness. Under 5% labeled data, DACL improves Dice by up to 2.77% and reduces HD95 by up to 14.69 mm compared with the strongest recent semi-supervised methods, demonstrating significant improvements in boundary accuracy on both fetal head and abdomen datasets. These results demonstrate the effectiveness of agreement-based consistency learning for annotation-efficient fetal US segmentation. Our code is on GitHub.
A Clinician-Centered Pipeline for Annotation and Evaluation in Ultrasound AI Studies
Jun 17, 2026Clinician-centered evaluation is critical for validating medical AI systems, especially in ultrasound imaging where quantitative metrics do not always capture clinical usability. Existing medical image platforms primarily focus on dataset labeling. They lack integrated support for blinded model comparison and reproducible evaluation workflows. We present a clinician-centered pipeline for remote annotation and evaluation in ultrasound AI studies. The proposed pipeline uses a centralized server and lightweight browser interfaces to enable clinicians to perform annotation, blinded ranking, and review without local dataset downloads. The pipeline also supports multi-rater participation, centralized result aggregation, and automated statistical analysis. We validate the pipeline in a fetal ultrasound segmentation study with six raters spanning expert, generalist, and non-expert experience levels. The system automatically generated Spearman correlation, Kendall's $τ$, and top-1 selection statistics. Results indicated moderate to strong agreement across experts and other groups. The blinded evaluation results showed a tendency for later active learning models to be preferred. These outcomes suggest that the pipeline can support clinician-centered annotation and reproducible human-\ac{AI} evaluation studies in ultrasound imaging. The proposed pipeline is available on \href{https://github.com/13204942/SonoRate}{GitHub}.
DyABD: The Abdominal Muscle Segmentation in Dynamic MRI Benchmark
Apr 25, 2026This work introduces DyABD, a novel and complex benchmark dataset of dynamic abdominal MRIs from patients with abdominal hernias and associated high quality abdominal muscle annotations. DyABD is the first-of-its-kind in four key ways; (1) it proposes the first abdominal muscle segmentation task, (2) the dynamic MRIs are acquired whilst the patients perform various exercises, introducing extreme anatomical variability, making it one of the most challenging segmentation datasets to date, (3) it includes both pre and post corrective MRIs and (4) DyABD promotes clinical research into the high recurrence rates of abdominal hernias. Beyond dataset introduction, this work provides a comprehensive evaluation of the generalisation capabilities of existing segmentation models across Supervised, Few Shot and Zero Shot paradigms on the unseen DyABD dataset. This work reveals that there is still room for substantial improvement in the field of medical image segmentation, with the majority of techniques achieving a Dice Coefficient of 0.82. This work therefore sheds light on the true progress of the field and redefines the benchmark for progress in medical image segmentation.
Are Natural-Domain Foundation Models Effective for Accelerated Cardiac MRI Reconstruction?
Apr 24, 2026The emergence of large-scale pretrained foundation models has transformed computer vision, enabling strong performance across diverse downstream tasks. However, their potential for physics-based inverse problems, such as accelerated cardiac MRI reconstruction, remains largely underexplored. In this work, we investigate whether natural-domain foundation models can serve as effective image priors for accelerated cardiac MRI reconstruction, and compare the performance obtained against domain-specific counterparts such as BiomedCLIP. We propose an unrolled reconstruction framework that incorporates pretrained, frozen visual encoders, such as CLIP, DINOv2, and BiomedCLIP, within each cascade to guide the reconstruction process. Through extensive experiments, we show that while task-specific state-of-the-art reconstruction models such as E2E-VarNet achieve superior performance in standard in-distribution settings, foundation-model-based approaches remain competitive. More importantly, in challenging cross-domain scenarios, where models are trained on cardiac MRI and evaluated on anatomically distinct knee and brain datasets--foundation models exhibit improved robustness, particularly under high acceleration factors and limited low-frequency sampling. We further observe that natural-image-pretrained models, such as CLIP, learn highly transferable structural representations, while domain-specific pretraining (BiomedCLIP) provides modest additional gains in more ill-posed regimes. Overall, our results suggest that pretrained foundation models offer a promising source of transferable priors, enabling improved robustness and generalization in accelerated MRI reconstruction.
Cross-Modal Knowledge Distillation for PET-Free Amyloid-Beta Detection from MRI
Apr 14, 2026Detecting amyloid-$β$ (A$β$) positivity is crucial for early diagnosis of Alzheimer's disease but typically requires PET imaging, which is costly, invasive, and not widely accessible, limiting its use for population-level screening. We address this gap by proposing a PET-guided knowledge distillation framework that enables A$β$ prediction from MRI alone, without requiring non-imaging clinical covariates or PET at inference. Our approach employs a BiomedCLIP-based teacher model that learns PET-MRI alignment via cross-modal attention and triplet contrastive learning with PET-informed (Centiloid-aware) online negative sampling. An MRI-only student then mimics the teacher via feature-level and logit-level distillation. Evaluated across four MRI contrasts (T1w, T2w, FLAIR, T2*) and two independent datasets, our approach demonstrates effective knowledge transfer (best AUC: 0.74 on OASIS-3, 0.68 on ADNI) while maintaining interpretability and eliminating the need for clinical variables. Saliency analysis confirms that predictions focus on anatomically relevant cortical regions, supporting the clinical viability of PET-free A$β$ screening. Code is available at https://github.com/FrancescoChiumento/pet-guided-mri-amyloid-detection.
Understanding Task Aggregation for Generalizable Ultrasound Foundation Models
Mar 18, 2026Foundation models promise to unify multiple clinical tasks within a single framework, but recent ultrasound studies report that unified models can underperform task-specific baselines. We hypothesize that this degradation arises not from model capacity limitations, but from task aggregation strategies that ignore interactions between task heterogeneity and available training data scale. In this work, we systematically analyze when heterogeneous ultrasound tasks can be jointly learned without performance loss, establishing practical criteria for task aggregation in unified clinical imaging models. We introduce M2DINO, a multi-organ, multi-task framework built on DINOv3 with task-conditioned Mixture-of-Experts blocks for adaptive capacity allocation. We systematically evaluate 27 ultrasound tasks spanning segmentation, classification, detection, and regression under three paradigms: task-specific, clinically-grouped, and all-task unified training. Our results show that aggregation effectiveness depends strongly on training data scale. While clinically-grouped training can improve performance in data-rich settings, it may induce substantial negative transfer in low-data settings. In contrast, all-task unified training exhibits more consistent performance across clinical groups. We further observe that task sensitivity varies by task type in our experiments: segmentation shows the largest performance drops compared with regression and classification. These findings provide practical guidance for ultrasound foundation models, emphasizing that aggregation strategies should jointly consider training data availability and task characteristics rather than relying on clinical taxonomy alone.
Dual Agreement Consistency Learning with Foundation Models for Semi-Supervised Fetal Heart Ultrasound Segmentation and Diagnosis
Mar 18, 2026Congenital heart disease (CHD) screening from fetal echocardiography requires accurate analysis of multiple standard cardiac views, yet developing reliable artificial intelligence models remains challenging due to limited annotations and variable image quality. In this work, we propose FM-DACL, a semi-supervised Dual Agreement Consistency Learning framework for the FETUS 2026 challenge on fetal heart ultrasound segmentation and diagnosis. The method combines a pretrained ultrasound foundation model (EchoCare) with a convolutional network through heterogeneous co-training and an exponential moving average teacher to better exploit unlabeled data. Experiments on the multi-center challenge dataset show that FM-DACL achieves a Dice score of 59.66 and NSD of 42.82 using heterogeneous backbones, demonstrating the feasibility of the proposed semi-supervised framework. These results suggest that FM-DACL provides a flexible approach for leveraging heterogeneous models in low-annotation fetal cardiac ultrasound analysis. The code is available on https://github.com/13204942/FM-DACL.
Entropy-Guided Agreement-Diversity: A Semi-Supervised Active Learning Framework for Fetal Head Segmentation in Ultrasound
Jan 24, 2026Fetal ultrasound (US) data is often limited due to privacy and regulatory restrictions, posing challenges for training deep learning (DL) models. While semi-supervised learning (SSL) is commonly used for fetal US image analysis, existing SSL methods typically rely on random limited selection, which can lead to suboptimal model performance by overfitting to homogeneous labeled data. To address this, we propose a two-stage Active Learning (AL) sampler, Entropy-Guided Agreement-Diversity (EGAD), for fetal head segmentation. Our method first selects the most uncertain samples using predictive entropy, and then refines the final selection using the agreement-diversity score combining cosine similarity and mutual information. Additionally, our SSL framework employs a consistency learning strategy with feature downsampling to further enhance segmentation performance. In experiments, SSL-EGAD achieves an average Dice score of 94.57\% and 96.32\% on two public datasets for fetal head segmentation, using 5\% and 10\% labeled data for training, respectively. Our method outperforms current SSL models and showcases consistent robustness across diverse pregnancy stage data. The code is available on \href{https://github.com/13204942/Semi-supervised-EGAD}{GitHub}.
Parameter-Free Bio-Inspired Channel Attention for Enhanced Cardiac MRI Reconstruction
May 29, 2025Attention is a fundamental component of the human visual recognition system. The inclusion of attention in a convolutional neural network amplifies relevant visual features and suppresses the less important ones. Integrating attention mechanisms into convolutional neural networks enhances model performance and interpretability. Spatial and channel attention mechanisms have shown significant advantages across many downstream tasks in medical imaging. While existing attention modules have proven to be effective, their design often lacks a robust theoretical underpinning. In this study, we address this gap by proposing a non-linear attention architecture for cardiac MRI reconstruction and hypothesize that insights from ecological principles can guide the development of effective and efficient attention mechanisms. Specifically, we investigate a non-linear ecological difference equation that describes single-species population growth to devise a parameter-free attention module surpassing current state-of-the-art parameter-free methods.
Segmenting Fetal Head with Efficient Fine-tuning Strategies in Low-resource Settings: an empirical study with U-Net
Jul 29, 2024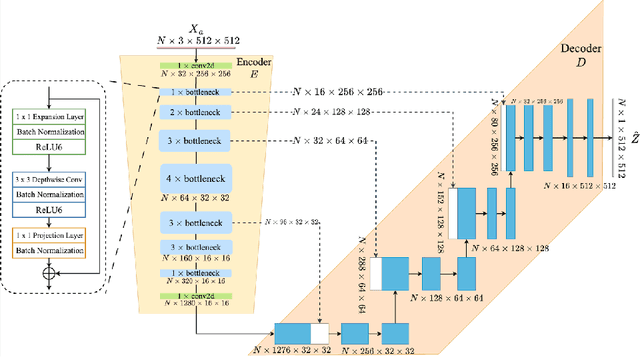
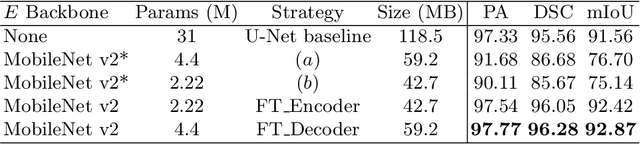
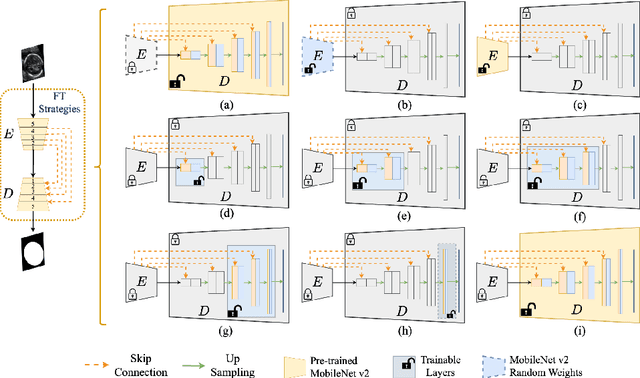
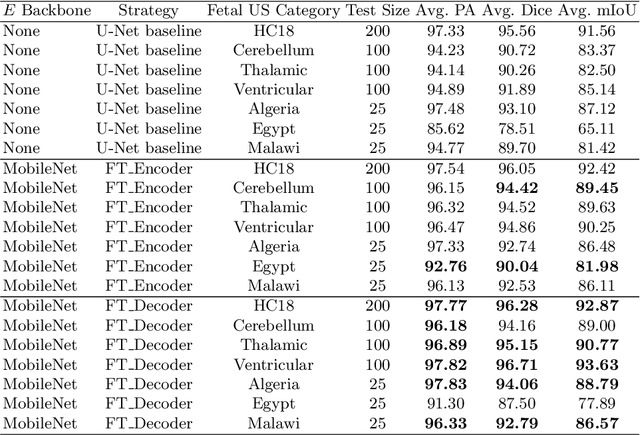
Accurate measurement of fetal head circumference is crucial for estimating fetal growth during routine prenatal screening. Prior to measurement, it is necessary to accurately identify and segment the region of interest, specifically the fetal head, in ultrasound images. Recent advancements in deep learning techniques have shown significant progress in segmenting the fetal head using encoder-decoder models. Among these models, U-Net has become a standard approach for accurate segmentation. However, training an encoder-decoder model can be a time-consuming process that demands substantial computational resources. Moreover, fine-tuning these models is particularly challenging when there is a limited amount of data available. There are still no "best-practice" guidelines for optimal fine-tuning of U-net for fetal ultrasound image segmentation. This work summarizes existing fine-tuning strategies with various backbone architectures, model components, and fine-tuning strategies across ultrasound data from Netherlands, Spain, Malawi, Egypt and Algeria. Our study shows that (1) fine-tuning U-Net leads to better performance than training from scratch, (2) fine-tuning strategies in decoder are superior to other strategies, (3) network architecture with less number of parameters can achieve similar or better performance. We also demonstrate the effectiveness of fine-tuning strategies in low-resource settings and further expand our experiments into few-shot learning. Lastly, we publicly released our code and specific fine-tuned weights.