 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidation of Conformal Prediction in Cervical Atypia Classification
May 13, 2025Deep learning based cervical cancer classification can potentially increase access to screening in low-resource regions. However, deep learning models are often overconfident and do not reliably reflect diagnostic uncertainty. Moreover, they are typically optimized to generate maximum-likelihood predictions, which fail to convey uncertainty or ambiguity in their results. Such challenges can be addressed using conformal prediction, a model-agnostic framework for generating prediction sets that contain likely classes for trained deep-learning models. The size of these prediction sets indicates model uncertainty, contracting as model confidence increases. However, existing conformal prediction evaluation primarily focuses on whether the prediction set includes or covers the true class, often overlooking the presence of extraneous classes. We argue that prediction sets should be truthful and valuable to end users, ensuring that the listed likely classes align with human expectations rather than being overly relaxed and including false positives or unlikely classes. In this study, we comprehensively validate conformal prediction sets using expert annotation sets collected from multiple annotators. We evaluate three conformal prediction approaches applied to three deep-learning models trained for cervical atypia classification. Our expert annotation-based analysis reveals that conventional coverage-based evaluations overestimate performance and that current conformal prediction methods often produce prediction sets that are not well aligned with human labels. Additionally, we explore the capabilities of the conformal prediction methods in identifying ambiguous and out-of-distribution data.
Distance-Aware eXplanation Based Learning
Sep 11, 2023



eXplanation Based Learning (XBL) is an interactive learning approach that provides a transparent method of training deep learning models by interacting with their explanations. XBL augments loss functions to penalize a model based on deviation of its explanations from user annotation of image features. The literature on XBL mostly depends on the intersection of visual model explanations and image feature annotations. We present a method to add a distance-aware explanation loss to categorical losses that trains a learner to focus on important regions of a training dataset. Distance is an appropriate approach for calculating explanation loss since visual model explanations such as Gradient-weighted Class Activation Mapping (Grad-CAMs) are not strictly bounded as annotations and their intersections may not provide complete information on the deviation of a model's focus from relevant image regions. In addition to assessing our model using existing metrics, we propose an interpretability metric for evaluating visual feature-attribution based model explanations that is more informative of the model's performance than existing metrics. We demonstrate performance of our proposed method on three image classification tasks.
Unlearning Spurious Correlations in Chest X-ray Classification
Aug 03, 2023Medical image classification models are frequently trained using training datasets derived from multiple data sources. While leveraging multiple data sources is crucial for achieving model generalization, it is important to acknowledge that the diverse nature of these sources inherently introduces unintended confounders and other challenges that can impact both model accuracy and transparency. A notable confounding factor in medical image classification, particularly in musculoskeletal image classification, is skeletal maturation-induced bone growth observed during adolescence. We train a deep learning model using a Covid-19 chest X-ray dataset and we showcase how this dataset can lead to spurious correlations due to unintended confounding regions. eXplanation Based Learning (XBL) is a deep learning approach that goes beyond interpretability by utilizing model explanations to interactively unlearn spurious correlations. This is achieved by integrating interactive user feedback, specifically feature annotations. In our study, we employed two non-demanding manual feedback mechanisms to implement an XBL-based approach for effectively eliminating these spurious correlations. Our results underscore the promising potential of XBL in constructing robust models even in the presence of confounding factors.
Learning from Exemplary Explanations
Jul 12, 2023eXplanation Based Learning (XBL) is a form of Interactive Machine Learning (IML) that provides a model refining approach via user feedback collected on model explanations. Although the interactivity of XBL promotes model transparency, XBL requires a huge amount of user interaction and can become expensive as feedback is in the form of detailed annotation rather than simple category labelling which is more common in IML. This expense is exacerbated in high stakes domains such as medical image classification. To reduce the effort and expense of XBL we introduce a new approach that uses two input instances and their corresponding Gradient Weighted Class Activation Mapping (GradCAM) model explanations as exemplary explanations to implement XBL. Using a medical image classification task, we demonstrate that, using minimal human input, our approach produces improved explanations (+0.02, +3%) and achieves reduced classification performance (-0.04, -4%) when compared against a model trained without interactions.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
FewSOME: Few Shot Anomaly Detection
Jan 20, 2023



Recent years have seen considerable progress in the field of Anomaly Detection but at the cost of increasingly complex training pipelines. Such techniques require large amounts of training data, resulting in computationally expensive algorithms. We propose Few Shot anomaly detection (FewSOME), a deep One-Class Anomaly Detection algorithm with the ability to accurately detect anomalies having trained on 'few' examples of the normal class and no examples of the anomalous class. We describe FewSOME to be of low complexity given its low data requirement and short training time. FewSOME is aided by pretrained weights with an architecture based on Siamese Networks. By means of an ablation study, we demonstrate how our proposed loss, 'Stop Loss', improves the robustness of FewSOME. Our experiments demonstrate that FewSOME performs at state-of-the-art level on benchmark datasets MNIST, CIFAR-10, F-MNIST and MVTec AD while training on only 30 normal samples, a minute fraction of the data that existing methods are trained on. Most notably, we found that FewSOME outperforms even highly complex models in the setting where only few examples of the normal class exist. Moreover, our extensive experiments show FewSOME to be robust to contaminated datasets. We also report F1 score and Balanced Accuracy in addition to AUC as a benchmark for future techniques to be compared against.
Identifying Spurious Correlations and Correcting them with an Explanation-based Learning
Dec 05, 2022
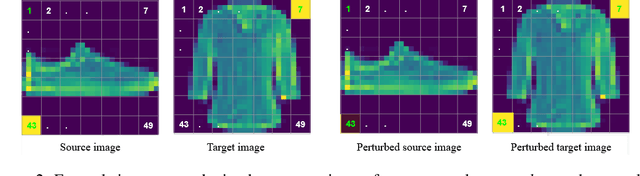
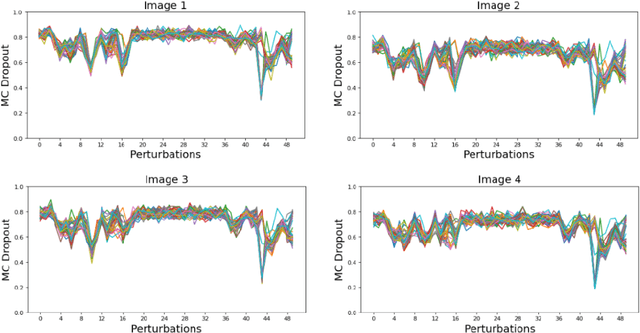
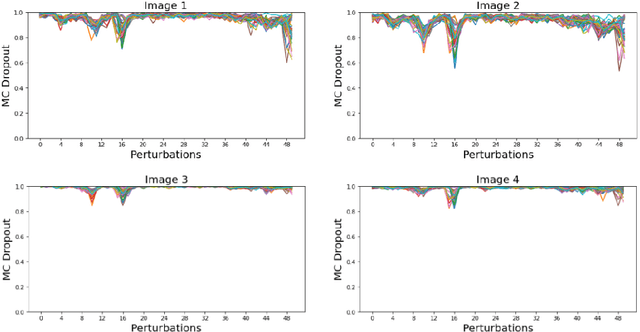
Identifying spurious correlations learned by a trained model is at the core of refining a trained model and building a trustworthy model. We present a simple method to identify spurious correlations that have been learned by a model trained for image classification problems. We apply image-level perturbations and monitor changes in certainties of predictions made using the trained model. We demonstrate this approach using an image classification dataset that contains images with synthetically generated spurious regions and show that the trained model was overdependent on spurious regions. Moreover, we remove the learned spurious correlations with an explanation based learning approach.
Impact of Feedback Type on Explanatory Interactive Learning
Sep 26, 2022Explanatory Interactive Learning (XIL) collects user feedback on visual model explanations to implement a Human-in-the-Loop (HITL) based interactive learning scenario. Different user feedback types will have different impacts on user experience and the cost associated with collecting feedback since different feedback types involve different levels of image annotation. Although XIL has been used to improve classification performance in multiple domains, the impact of different user feedback types on model performance and explanation accuracy is not well studied. To guide future XIL work we compare the effectiveness of two different user feedback types in image classification tasks: (1) instructing an algorithm to ignore certain spurious image features, and (2) instructing an algorithm to focus on certain valid image features. We use explanations from a Gradient-weighted Class Activation Mapping (GradCAM) based XIL model to support both feedback types. We show that identifying and annotating spurious image features that a model finds salient results in superior classification and explanation accuracy than user feedback that tells a model to focus on valid image features.
Posture Prediction for Healthy Sitting using a Smart Chair
Jan 05, 2022

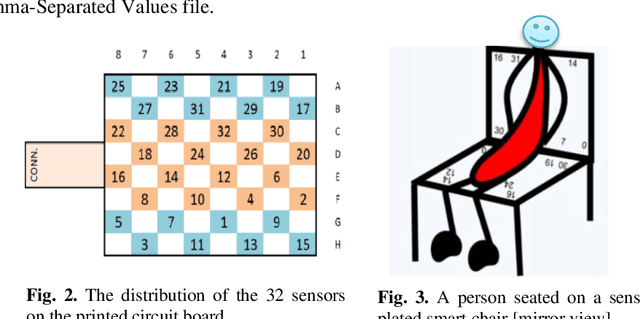

Poor sitting habits have been identified as a risk factor to musculoskeletal disorders and lower back pain especially on the elderly, disabled people, and office workers. In the current computerized world, even while involved in leisure or work activity, people tend to spend most of their days sitting at computer desks. This can result in spinal pain and related problems. Therefore, a means to remind people about their sitting habits and provide recommendations to counterbalance, such as physical exercise, is important. Posture recognition for seated postures have not received enough attention as most works focus on standing postures. Wearable sensors, pressure or force sensors, videos and images were used for posture recognition in the literature. The aim of this study is to build Machine Learning models for classifying sitting posture of a person by analyzing data collected from a chair platted with two 32 by 32 pressure sensors at its seat and backrest. Models were built using five algorithms: Random Forest (RF), Gaussian Na\"ive Bayes, Logistic Regression, Support Vector Machine and Deep Neural Network (DNN). All the models are evaluated using KFold cross-validation technique. This paper presents experiments conducted using the two separate datasets, controlled and realistic, and discusses results achieved at classifying six sitting postures. Average classification accuracies of 98% and 97% were achieved on the controlled and realistic datasets, respectively.
Optimising Knee Injury Detection with Spatial Attention and Validating Localisation Ability
Aug 18, 2021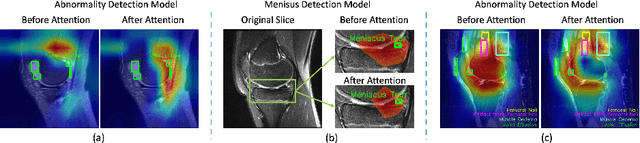


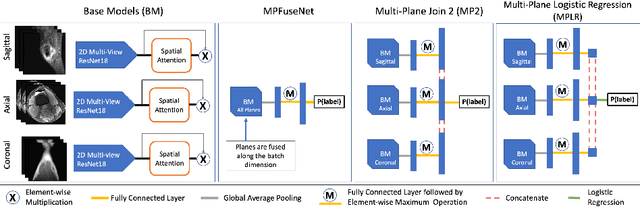
This work employs a pre-trained, multi-view Convolutional Neural Network (CNN) with a spatial attention block to optimise knee injury detection. An open-source Magnetic Resonance Imaging (MRI) data set with image-level labels was leveraged for this analysis. As MRI data is acquired from three planes, we compare our technique using data from a single-plane and multiple planes (multi-plane). For multi-plane, we investigate various methods of fusing the planes in the network. This analysis resulted in the novel 'MPFuseNet' network and state-of-the-art Area Under the Curve (AUC) scores for detecting Anterior Cruciate Ligament (ACL) tears and Abnormal MRIs, achieving AUC scores of 0.977 and 0.957 respectively. We then developed an objective metric, Penalised Localisation Accuracy (PLA), to validate the model's localisation ability. This metric compares binary masks generated from Grad-Cam output and the radiologist's annotations on a sample of MRIs. We also extracted explainability features in a model-agnostic approach that were then verified as clinically relevant by the radiologist.