 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Prediction: To Join or To Disjoin Datasets
Jun 12, 2025With the recent rise of generative Artificial Intelligence (AI), the need of selecting high-quality dataset to improve machine learning models has garnered increasing attention. However, some part of this topic remains underexplored, even for simple prediction models. In this work, we study the problem of developing practical algorithms that select appropriate dataset to minimize population loss of our prediction model with high probability. Broadly speaking, we investigate when datasets from different sources can be effectively merged to enhance the predictive model's performance, and propose a practical algorithm with theoretical guarantees. By leveraging an oracle inequality and data-driven estimators, the algorithm reduces population loss with high probability. Numerical experiments demonstrate its effectiveness in both standard linear regression and broader machine learning applications. Code is available at https://github.com/kkrokii/collaborative_prediction.
Incentivizing High-Quality Human Annotations with Golden Questions
May 25, 2025Human-annotated data plays a vital role in training large language models (LLMs), such as supervised fine-tuning and human preference alignment. However, it is not guaranteed that paid human annotators produce high-quality data. In this paper, we study how to incentivize human annotators to do so. We start from a principal-agent model to model the dynamics between the company (the principal) and the annotator (the agent), where the principal can only monitor the annotation quality by examining $n$ samples. We investigate the maximum likelihood estimators (MLE) and the corresponding hypothesis testing to incentivize annotators: the agent is given a bonus if the MLE passes the test. By analyzing the variance of the outcome, we show that the strategic behavior of the agent makes the hypothesis testing very different from traditional ones: Unlike the exponential rate proved by the large deviation theory, the principal-agent model's hypothesis testing rate is of $\Theta(1/\sqrt{n \log n})$. Our theory implies two criteria for the \emph{golden questions} to monitor the performance of the annotators: they should be of (1) high certainty and (2) similar format to normal ones. In that light, we select a set of golden questions in human preference data. By doing incentive-compatible experiments, we find out that the annotators' behavior is better revealed by those golden questions, compared to traditional survey techniques such as instructed manipulation checks.
OMGPT: A Sequence Modeling Framework for Data-driven Operational Decision Making
May 19, 2025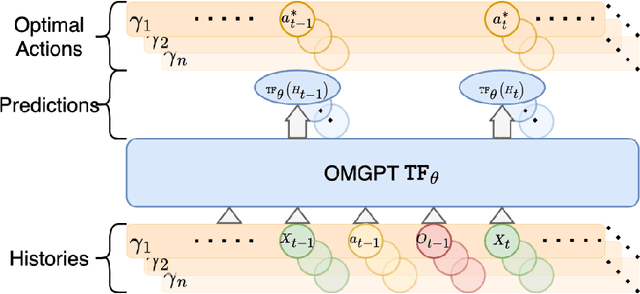



We build a Generative Pre-trained Transformer (GPT) model from scratch to solve sequential decision making tasks arising in contexts of operations research and management science which we call OMGPT. We first propose a general sequence modeling framework to cover several operational decision making tasks as special cases, such as dynamic pricing, inventory management, resource allocation, and queueing control. Under the framework, all these tasks can be viewed as a sequential prediction problem where the goal is to predict the optimal future action given all the historical information. Then we train a transformer-based neural network model (OMGPT) as a natural and powerful architecture for sequential modeling. This marks a paradigm shift compared to the existing methods for these OR/OM tasks in that (i) the OMGPT model can take advantage of the huge amount of pre-trained data; (ii) when tackling these problems, OMGPT does not assume any analytical model structure and enables a direct and rich mapping from the history to the future actions. Either of these two aspects, to the best of our knowledge, is not achieved by any existing method. We establish a Bayesian perspective to theoretically understand the working mechanism of the OMGPT on these tasks, which relates its performance with the pre-training task diversity and the divergence between the testing task and pre-training tasks. Numerically, we observe a surprising performance of the proposed model across all the above tasks.
How Humans Help LLMs: Assessing and Incentivizing Human Preference Annotators
Feb 10, 2025Human-annotated preference data play an important role in aligning large language models (LLMs). In this paper, we investigate the questions of assessing the performance of human annotators and incentivizing them to provide high-quality annotations. The quality assessment of language/text annotation faces two challenges: (i) the intrinsic heterogeneity among annotators, which prevents the classic methods that assume the underlying existence of a true label; and (ii) the unclear relationship between the annotation quality and the performance of downstream tasks, which excludes the possibility of inferring the annotators' behavior based on the model performance trained from the annotation data. Then we formulate a principal-agent model to characterize the behaviors of and the interactions between the company and the human annotators. The model rationalizes a practical mechanism of a bonus scheme to incentivize annotators which benefits both parties and it underscores the importance of the joint presence of an assessment system and a proper contract scheme. From a technical perspective, our analysis extends the existing literature on the principal-agent model by considering a continuous action space for the agent. We show the gap between the first-best and the second-best solutions (under the continuous action space) is of $\Theta(1/\sqrt{n \log n})$ for the binary contracts and $\Theta(1/n)$ for the linear contracts, where $n$ is the number of samples used for performance assessment; this contrasts with the known result of $\exp(-\Theta(n))$ for the binary contracts when the action space is discrete. Throughout the paper, we use real preference annotation data to accompany our discussions.
Reward Modeling with Ordinal Feedback: Wisdom of the Crowd
Nov 19, 2024



Learning a reward model (RM) from human preferences has been an important component in aligning large language models (LLMs). The canonical setup of learning RMs from pairwise preference data is rooted in the classic Bradley-Terry (BT) model that accepts binary feedback, i.e., the label being either Response 1 is better than Response 2, or the opposite. Such a setup inevitably discards potentially useful samples (such as "tied" between the two responses) and loses more fine-grained information (such as "slightly better"). In this paper, we propose a framework for learning RMs under ordinal feedback which generalizes the case of binary preference feedback to any arbitrary granularity. Specifically, we first identify a marginal unbiasedness condition, which generalizes the assumption of the BT model in the existing binary feedback setting. The condition validates itself via the sociological concept of the wisdom of the crowd. Under the condition, we develop a natural probability model for pairwise preference data under ordinal feedback and analyze its properties. We prove the statistical benefits of ordinal feedback in terms of reducing the Rademacher complexity compared to the case of binary feedback. The proposed learning objective and the theory also extend to hinge loss and direct policy optimization (DPO). In particular, the theoretical analysis may be of independent interest when applying to a seemingly unrelated problem of knowledge distillation to interpret the bias-variance trade-off therein. The framework also sheds light on writing guidance for human annotators. Our numerical experiments validate that fine-grained feedback leads to better reward learning for both in-distribution and out-of-distribution settings. Further experiments show that incorporating a certain proportion of samples with tied preference boosts RM learning.
Towards Better Understanding of In-Context Learning Ability from In-Context Uncertainty Quantification
May 24, 2024



Predicting simple function classes has been widely used as a testbed for developing theory and understanding of the trained Transformer's in-context learning (ICL) ability. In this paper, we revisit the training of Transformers on linear regression tasks, and different from all the existing literature, we consider a bi-objective prediction task of predicting both the conditional expectation $\mathbb{E}[Y|X]$ and the conditional variance Var$(Y|X)$. This additional uncertainty quantification objective provides a handle to (i) better design out-of-distribution experiments to distinguish ICL from in-weight learning (IWL) and (ii) make a better separation between the algorithms with and without using the prior information of the training distribution. Theoretically, we show that the trained Transformer reaches near Bayes-optimum, suggesting the usage of the information of the training distribution. Our method can be extended to other cases. Specifically, with the Transformer's context window $S$, we prove a generalization bound of $\tilde{\mathcal{O}}(\sqrt{\min\{S, T\}/(n T)})$ on $n$ tasks with sequences of length $T$, providing sharper analysis compared to previous results of $\tilde{\mathcal{O}}(\sqrt{1/n})$. Empirically, we illustrate that while the trained Transformer behaves as the Bayes-optimal solution as a natural consequence of supervised training in distribution, it does not necessarily perform a Bayesian inference when facing task shifts, in contrast to the \textit{equivalence} between these two proposed in many existing literature. We also demonstrate the trained Transformer's ICL ability over covariates shift and prompt-length shift and interpret them as a generalization over a meta distribution.
Understanding the Training and Generalization of Pretrained Transformer for Sequential Decision Making
May 23, 2024



In this paper, we consider the supervised pretrained transformer for a class of sequential decision-making problems. The class of considered problems is a subset of the general formulation of reinforcement learning in that there is no transition probability matrix, and the class of problems covers bandits, dynamic pricing, and newsvendor problems as special cases. Such a structure enables the use of optimal actions/decisions in the pretraining phase, and the usage also provides new insights for the training and generalization of the pretrained transformer. We first note that the training of the transformer model can be viewed as a performative prediction problem, and the existing methods and theories largely ignore or cannot resolve the arisen out-of-distribution issue. We propose a natural solution that includes the transformer-generated action sequences in the training procedure, and it enjoys better properties both numerically and theoretically. The availability of the optimal actions in the considered tasks also allows us to analyze the properties of the pretrained transformer as an algorithm and explains why it may lack exploration and how this can be automatically resolved. Numerically, we categorize the advantages of the pretrained transformer over the structured algorithms such as UCB and Thompson sampling into three cases: (i) it better utilizes the prior knowledge in the pretraining data; (ii) it can elegantly handle the misspecification issue suffered by the structured algorithms; (iii) for short time horizon such as $T\le50$, it behaves more greedy and enjoys much better regret than the structured algorithms which are designed for asymptotic optimality.
Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach
Apr 24, 2024



Large language models (LLMs) are highly capable of many tasks but they can sometimes generate unreliable or inaccurate outputs. To tackle this issue, this paper studies the problem of uncertainty estimation and calibration for LLMs. We begin by formulating the uncertainty estimation problem for LLMs and then propose a supervised approach that takes advantage of the labeled datasets and estimates the uncertainty of the LLMs' responses. Based on the formulation, we illustrate the difference between the uncertainty estimation for LLMs and that for standard ML models and explain why the hidden activations of the LLMs contain uncertainty information. Our designed approach effectively demonstrates the benefits of utilizing hidden activations for enhanced uncertainty estimation across various tasks and shows robust transferability in out-of-distribution settings. Moreover, we distinguish the uncertainty estimation task from the uncertainty calibration task and show that a better uncertainty estimation mode leads to a better calibration performance. In practice, our method is easy to implement and is adaptable to different levels of model transparency including black box, grey box, and white box, each demonstrating strong performance based on the accessibility of the LLM's internal mechanisms.
Towards Better Statistical Understanding of Watermarking LLMs
Mar 19, 2024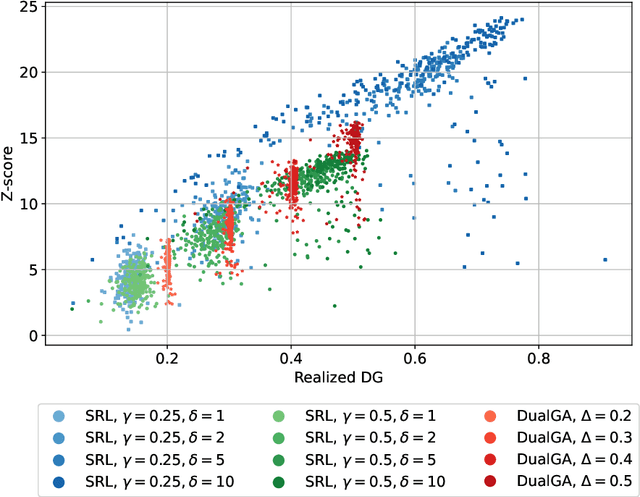
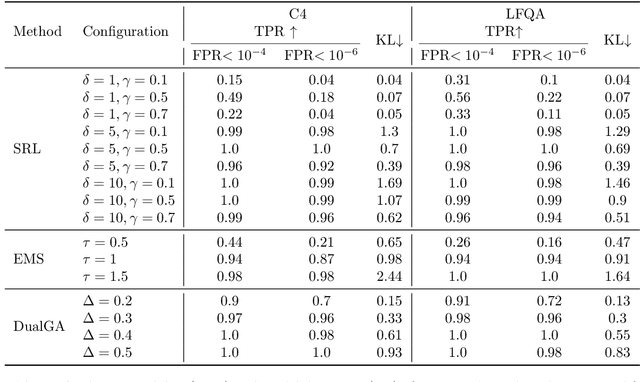
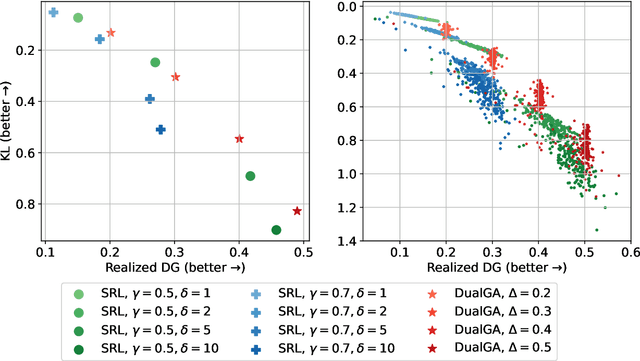
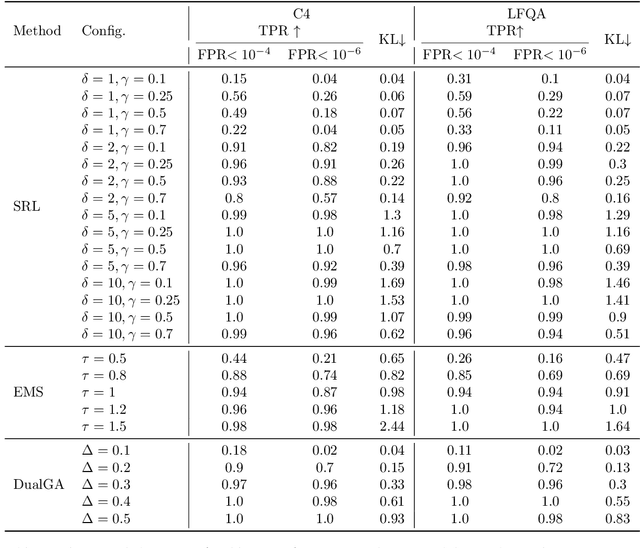
In this paper, we study the problem of watermarking large language models (LLMs). We consider the trade-off between model distortion and detection ability and formulate it as a constrained optimization problem based on the green-red algorithm of Kirchenbauer et al. (2023a). We show that the optimal solution to the optimization problem enjoys a nice analytical property which provides a better understanding and inspires the algorithm design for the watermarking process. We develop an online dual gradient ascent watermarking algorithm in light of this optimization formulation and prove its asymptotic Pareto optimality between model distortion and detection ability. Such a result guarantees an averaged increased green list probability and henceforth detection ability explicitly (in contrast to previous results). Moreover, we provide a systematic discussion on the choice of the model distortion metrics for the watermarking problem. We justify our choice of KL divergence and present issues with the existing criteria of ``distortion-free'' and perplexity. Finally, we empirically evaluate our algorithms on extensive datasets against benchmark algorithms.
Transformer Choice Net: A Transformer Neural Network for Choice Prediction
Oct 12, 2023



Discrete-choice models, such as Multinomial Logit, Probit, or Mixed-Logit, are widely used in Marketing, Economics, and Operations Research: given a set of alternatives, the customer is modeled as choosing one of the alternatives to maximize a (latent) utility function. However, extending such models to situations where the customer chooses more than one item (such as in e-commerce shopping) has proven problematic. While one can construct reasonable models of the customer's behavior, estimating such models becomes very challenging because of the combinatorial explosion in the number of possible subsets of items. In this paper we develop a transformer neural network architecture, the Transformer Choice Net, that is suitable for predicting multiple choices. Transformer networks turn out to be especially suitable for this task as they take into account not only the features of the customer and the items but also the context, which in this case could be the assortment as well as the customer's past choices. On a range of benchmark datasets, our architecture shows uniformly superior out-of-sample prediction performance compared to the leading models in the literature, without requiring any custom modeling or tuning for each instance.