 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Statistical Understanding of Watermarking LLMs
Paper and Code
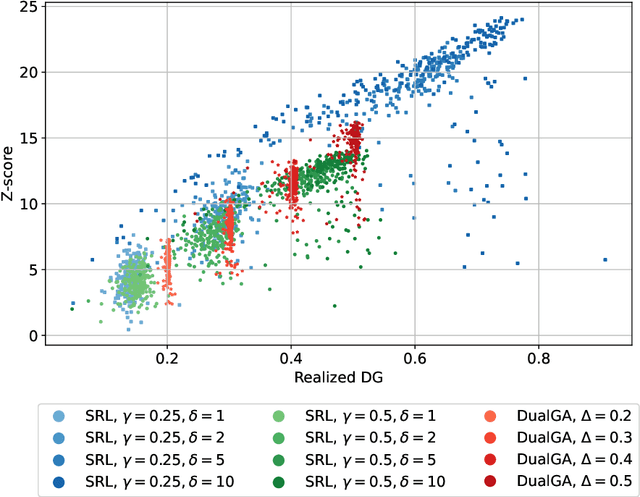
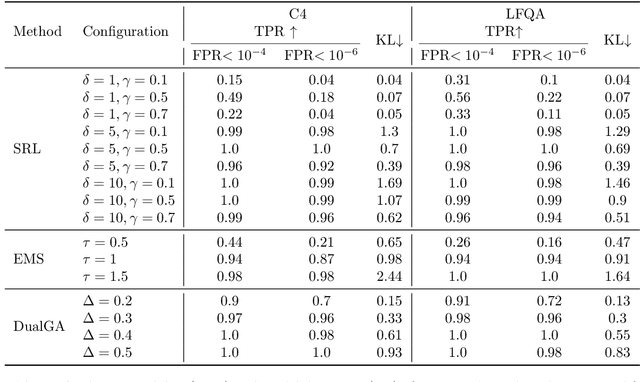
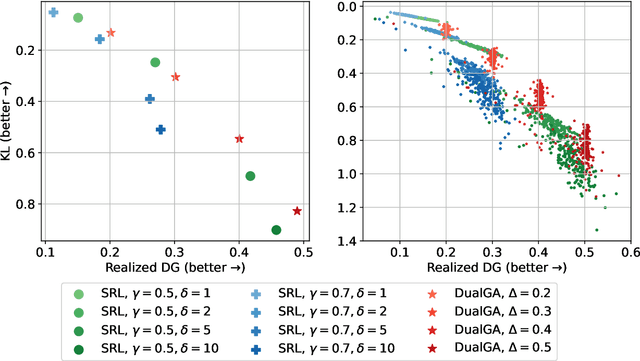
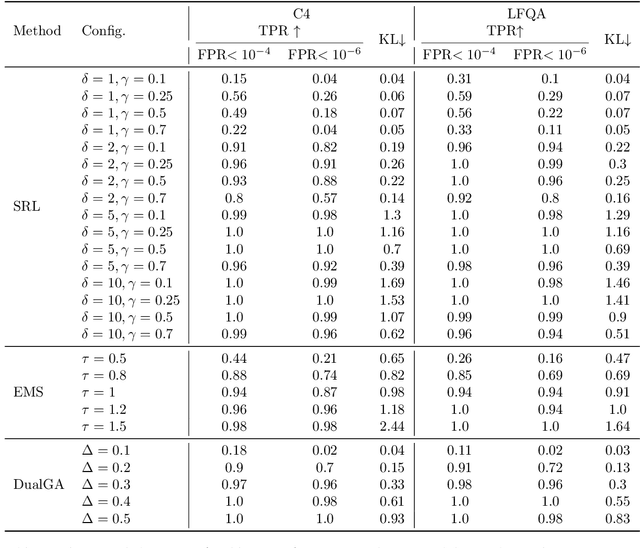
In this paper, we study the problem of watermarking large language models (LLMs). We consider the trade-off between model distortion and detection ability and formulate it as a constrained optimization problem based on the green-red algorithm of Kirchenbauer et al. (2023a). We show that the optimal solution to the optimization problem enjoys a nice analytical property which provides a better understanding and inspires the algorithm design for the watermarking process. We develop an online dual gradient ascent watermarking algorithm in light of this optimization formulation and prove its asymptotic Pareto optimality between model distortion and detection ability. Such a result guarantees an averaged increased green list probability and henceforth detection ability explicitly (in contrast to previous results). Moreover, we provide a systematic discussion on the choice of the model distortion metrics for the watermarking problem. We justify our choice of KL divergence and present issues with the existing criteria of ``distortion-free'' and perplexity. Finally, we empirically evaluate our algorithms on extensive datasets against benchmark algorithms.