 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Prompt Learning: Continual Adapter for Efficient Rehearsal-Free Continual Learning
Paper and Code
Jul 14, 2024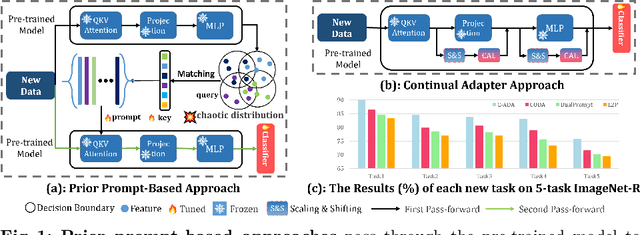
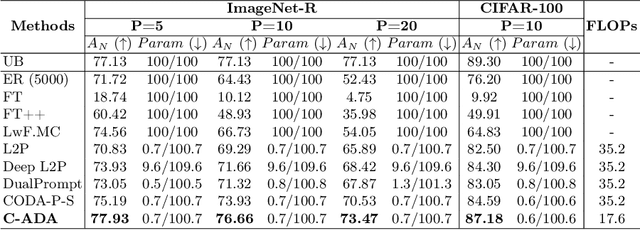
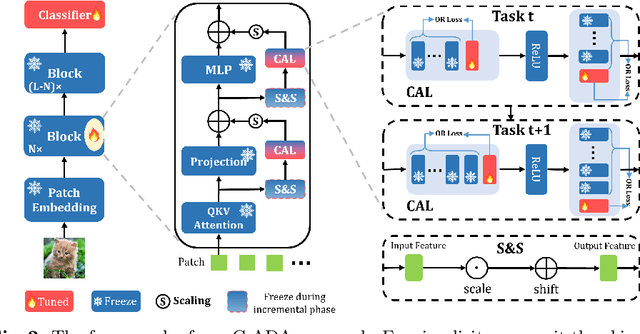
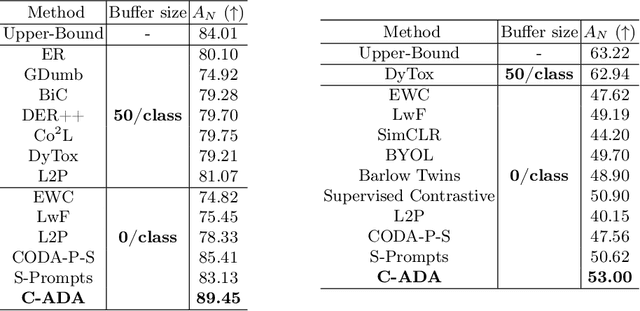
The problem of Rehearsal-Free Continual Learning (RFCL) aims to continually learn new knowledge while preventing forgetting of the old knowledge, without storing any old samples and prototypes. The latest methods leverage large-scale pre-trained models as the backbone and use key-query matching to generate trainable prompts to learn new knowledge. However, the domain gap between the pre-training dataset and the downstream datasets can easily lead to inaccuracies in key-query matching prompt selection when directly generating queries using the pre-trained model, which hampers learning new knowledge. Thus, in this paper, we propose a beyond prompt learning approach to the RFCL task, called Continual Adapter (C-ADA). It mainly comprises a parameter-extensible continual adapter layer (CAL) and a scaling and shifting (S&S) module in parallel with the pre-trained model. C-ADA flexibly extends specific weights in CAL to learn new knowledge for each task and freezes old weights to preserve prior knowledge, thereby avoiding matching errors and operational inefficiencies introduced by key-query matching. To reduce the gap, C-ADA employs an S&S module to transfer the feature space from pre-trained datasets to downstream datasets. Moreover, we propose an orthogonal loss to mitigate the interaction between old and new knowledge. Our approach achieves significantly improved performance and training speed, outperforming the current state-of-the-art (SOTA) method. Additionally, we conduct experiments on domain-incremental learning, surpassing the SOTA, and demonstrating the generality of our approach in different settings.