 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFU-MPC: Frontier- and Uncertainty-Aware Model Predictive Control for Efficient and Accurate UAV Exploration with Motorized LiDAR
May 14, 2026Efficient UAV exploration in unknown environments requires rapid coverage expansion while maintaining accurate and reliable localization, since safe navigation in complex scenes depends on consistent mapping and pose estimation. However, for conventional LiDAR-equipped UAVs, the observable region is tightly coupled with the UAV pose and motion. Expanding coverage often requires additional translational or rotational maneuvers, which can reduce exploration efficiency and increase the risk of localization degradation in geometrically challenging environments. Motorized rotating LiDARs provide a promising solution by actively adjusting the sensor viewing direction without changing the UAV motion, thereby introducing an additional sensing degree of freedom. Nevertheless, existing exploration systems rarely exploit this scanning freedom as an explicit decision variable linked to both exploration progress and localization quality. To address this gap, we develop a UAV platform equipped with an independently actuated rotating LiDAR and propose a hierarchical exploration framework. The global planner organizes frontiers into representative viewpoints and sequences them using topology-aware transition costs. Built upon this planner, FU-MPC serves as a local receding-horizon scan controller that optimizes LiDAR rotation along the predicted flight trajectory. The controller jointly considers frontier-aware exploration utility and direction-dependent localization uncertainty, while lightweight surrogate evaluation enables real-time onboard execution. Experiments in complex environments demonstrate that the proposed system improves exploration efficiency while maintaining robust localization performance compared with fixed-pattern scanning and uncertainty-only baselines. The project page can be found at https://kafeiyin00.github.io/FU-MPC/.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024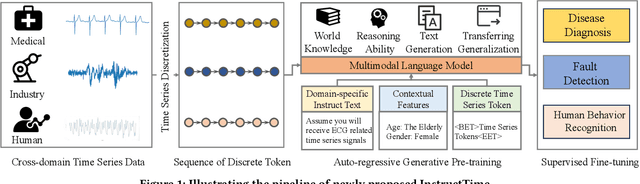
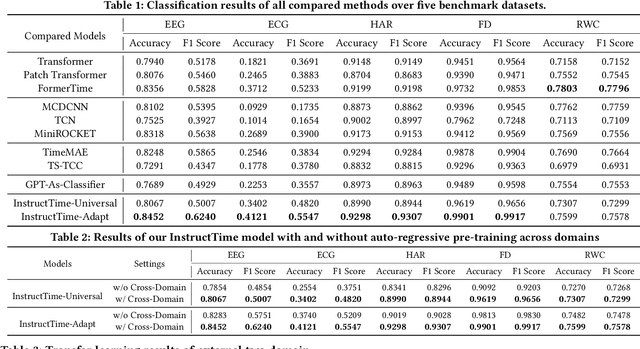

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.
Learning Transferable Time Series Classifier with Cross-Domain Pre-training from Language Model
Mar 19, 2024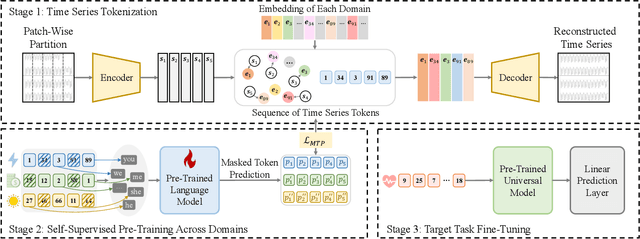



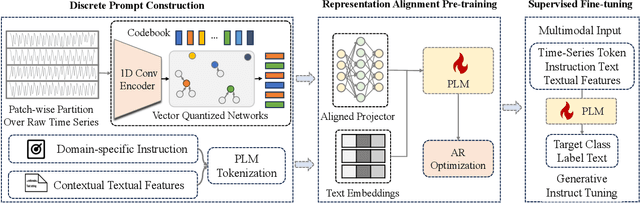
Advancements in self-supervised pre-training (SSL) have significantly advanced the field of learning transferable time series representations, which can be very useful in enhancing the downstream task. Despite being effective, most existing works struggle to achieve cross-domain SSL pre-training, missing valuable opportunities to integrate patterns and features from different domains. The main challenge lies in the significant differences in the characteristics of time-series data across different domains, such as variations in the number of channels and temporal resolution scales. To address this challenge, we propose CrossTimeNet, a novel cross-domain SSL learning framework to learn transferable knowledge from various domains to largely benefit the target downstream task. One of the key characteristics of CrossTimeNet is the newly designed time series tokenization module, which could effectively convert the raw time series into a sequence of discrete tokens based on a reconstruction optimization process. Besides, we highlight that predicting a high proportion of corrupted tokens can be very helpful for extracting informative patterns across different domains during SSL pre-training, which has been largely overlooked in past years. Furthermore, unlike previous works, our work treats the pre-training language model (PLM) as the initialization of the encoder network, investigating the feasibility of transferring the knowledge learned by the PLM to the time series area. Through these efforts, the path to cross-domain pre-training of a generic time series model can be effectively paved. We conduct extensive experiments in a real-world scenario across various time series classification domains. The experimental results clearly confirm CrossTimeNet's superior performance.