 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Auto-regressive Transformer for Effective Self-supervised Time Series Forecasting
Paper and Code
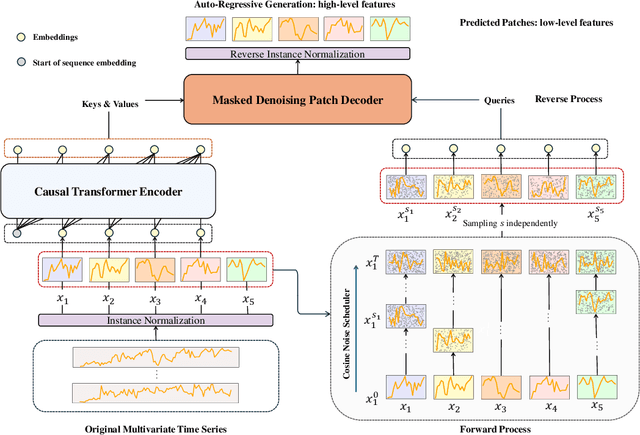
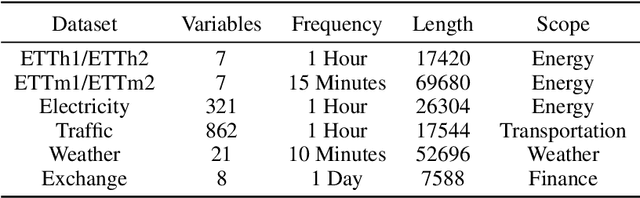
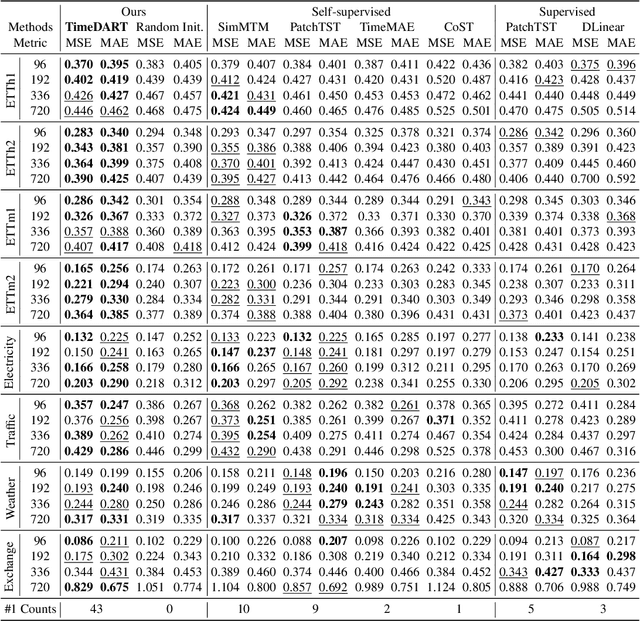
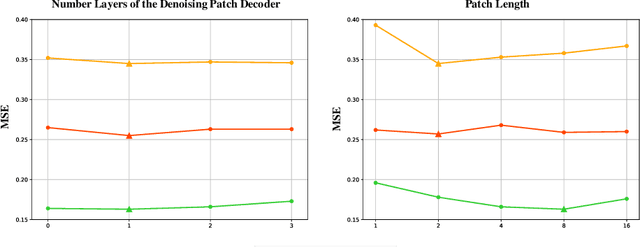
Self-supervised learning has become a popular and effective approach for enhancing time series forecasting, enabling models to learn universal representations from unlabeled data. However, effectively capturing both the global sequence dependence and local detail features within time series data remains challenging. To address this, we propose a novel generative self-supervised method called TimeDART, denoting Diffusion Auto-regressive Transformer for Time series forecasting. In TimeDART, we treat time series patches as basic modeling units. Specifically, we employ an self-attention based Transformer encoder to model the dependencies of inter-patches. Additionally, we introduce diffusion and denoising mechanisms to capture the detail locality features of intra-patch. Notably, we design a cross-attention-based denoising decoder that allows for adjustable optimization difficulty in the self-supervised task, facilitating more effective self-supervised pre-training. Furthermore, the entire model is optimized in an auto-regressive manner to obtain transferable representations. Extensive experiments demonstrate that TimeDART achieves state-of-the-art fine-tuning performance compared to the most advanced competitive methods in forecasting tasks. Our code is publicly available at https://github.com/Melmaphother/TimeDART.