 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACA-Net: Towards Lightweight Speaker Verification using Asymmetric Cross Attention
Paper and Code
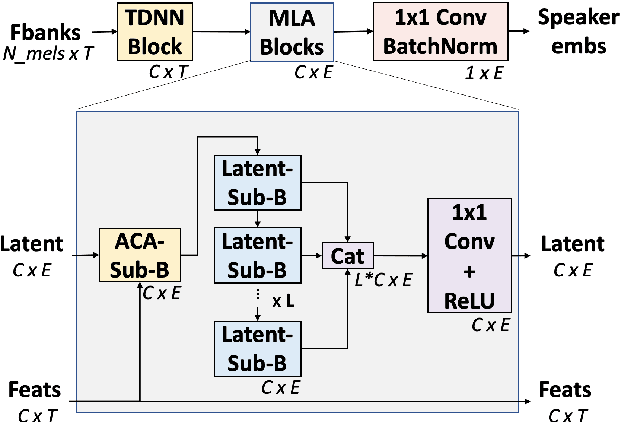
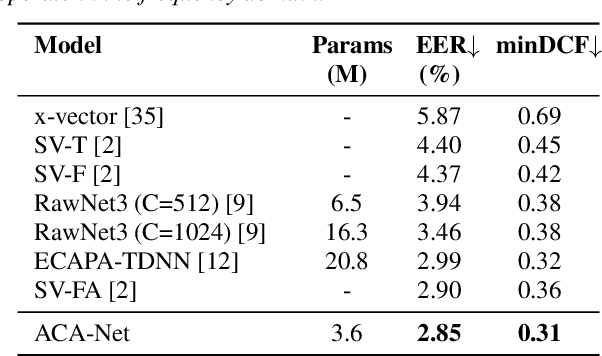
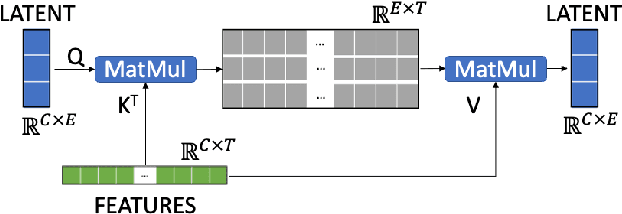
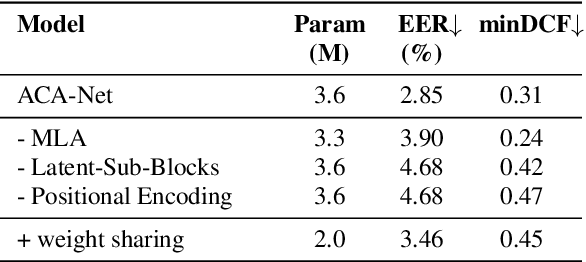
In this paper, we propose ACA-Net, a lightweight, global context-aware speaker embedding extractor for Speaker Verification (SV) that improves upon existing work by using Asymmetric Cross Attention (ACA) to replace temporal pooling. ACA is able to distill large, variable-length sequences into small, fixed-sized latents by attending a small query to large key and value matrices. In ACA-Net, we build a Multi-Layer Aggregation (MLA) block using ACA to generate fixed-sized identity vectors from variable-length inputs. Through global attention, ACA-Net acts as an efficient global feature extractor that adapts to temporal variability unlike existing SV models that apply a fixed function for pooling over the temporal dimension which may obscure information about the signal's non-stationary temporal variability. Our experiments on the WSJ0-1talker show ACA-Net outperforms a strong baseline by 5\% relative improvement in EER using only 1/5 of the parameters.