 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA correlation-permutation approach for speech-music encoders model merging
Jun 13, 2025Creating a unified speech and music model requires expensive pre-training. Model merging can instead create an unified audio model with minimal computational expense. However, direct merging is challenging when the models are not aligned in the weight space. Motivated by Git Re-Basin, we introduce a correlation-permutation approach that aligns a music encoder's internal layers with a speech encoder. We extend previous work to the case of merging transformer layers. The method computes a permutation matrix that maximizes the model's features-wise cross-correlations layer by layer, enabling effective fusion of these otherwise disjoint models. The merged model retains speech capabilities through this method while significantly enhancing music performance, achieving an improvement of 14.83 points in average score compared to linear interpolation model merging. This work allows the creation of unified audio models from independently trained encoders.
Distilling a speech and music encoder with task arithmetic
May 19, 2025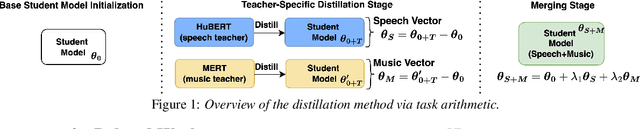
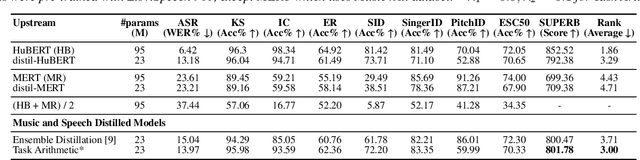
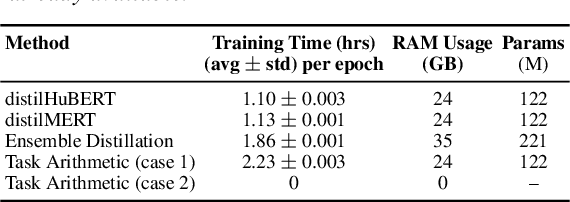
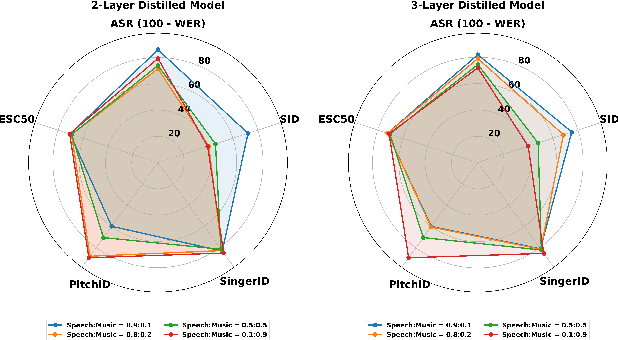
Despite the progress in self-supervised learning (SSL) for speech and music, existing models treat these domains separately, limiting their capacity for unified audio understanding. A unified model is desirable for applications that require general representations, e.g. audio large language models. Nonetheless, directly training a general model for speech and music is computationally expensive. Knowledge Distillation of teacher ensembles may be a natural solution, but we posit that decoupling the distillation of the speech and music SSL models allows for more flexibility. Thus, we propose to learn distilled task vectors and then linearly interpolate them to form a unified speech+music model. This strategy enables flexible domain emphasis through adjustable weights and is also simpler to train. Experiments on speech and music benchmarks demonstrate that our method yields superior overall performance compared to ensemble distillation.
Dataset-Distillation Generative Model for Speech Emotion Recognition
Jun 05, 2024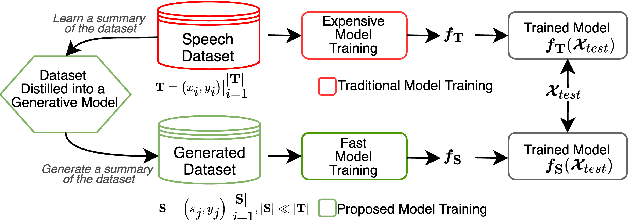

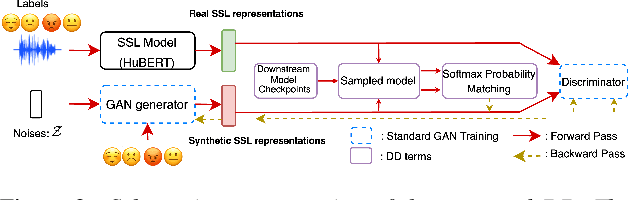
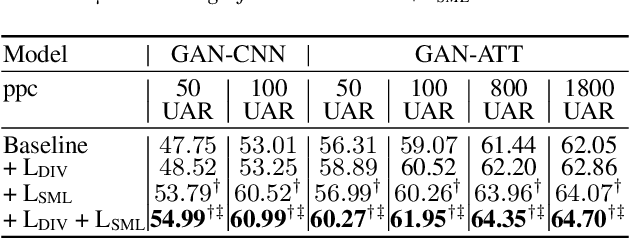
Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.