 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGVSC: A Large-Model-Driven Generative Video Semantic Communication Framework
Jun 11, 2026Driven by the massive video transmission requirements in the Internet of Everything, semantic communication holds great promise for striking a balance between transmission efficiency and quality. This paper introduces a large-model-driven generative video semantic communication (LGVSC) framework, enabling efficient video semantic transmission under extremely low bandwidth conditions. First, by decoupling the encoder and decoder as well as exposing explicit intermediate semantic representations, LGVSC maintains interpretability, avoiding the black-box behavior commonly observed in end-to-end systems. Next, we introduce a new metric, i.e., the probability-based semantic similarity score (PSSS), which quantifies semantic similarity for complex modalities within a continuous range, allowing for more precise evaluation of semantic content. Building on PSSS, we propose a semantic-guided keyframe extraction module driven by a multimodal large model. This module can enhance fine-grained semantic consistency during keyframe selection at the transmitter, optimizing transmission bandwidth without compromising semantic fidelity. Additionally, we design a generative large-model-driven dynamic semantic-adaptive decoder at the receiver, which can adapt to videos of arbitrary lengths. Simulation results demonstrate that LGVSC significantly outperforms traditional schemes, achieving a channel bandwidth ratio on the order of 10^-4 to 10^-3, while maintaining strong zero-shot generalization across downstream tasks.
Residual Cross-Attention Transformer-Based Multi-User CSI Feedback with Deep Joint Source-Channel Coding
May 26, 2025This letter proposes a deep-learning (DL)-based multi-user channel state information (CSI) feedback framework for massive multiple-input multiple-output systems, where the deep joint source-channel coding (DJSCC) is utilized to improve the CSI reconstruction accuracy. Specifically, we design a multi-user joint CSI feedback framework, whereby the CSI correlation of nearby users is utilized to reduce the feedback overhead. Under the framework, we propose a new residual cross-attention transformer architecture, which is deployed at the base station to further improve the CSI feedback performance. Moreover, to tackle the "cliff-effect" of conventional bit-level CSI feedback approaches, we integrated DJSCC into the multi-user CSI feedback, together with utilizing a two-stage training scheme to adapt to varying uplink noise levels. Experimental results demonstrate the superiority of our methods in CSI feedback performance, with low network complexity and better scalability.
ToDMA: Large Model-Driven Token-Domain Multiple Access for Semantic Communications
May 16, 2025Token communications (TokCom) is an emerging generative semantic communication concept that reduces transmission rates by using context and multimodal large language model (MLLM)-based token processing, with tokens serving as universal semantic units across modalities. In this paper, we propose a semantic multiple access scheme in the token domain, referred to as token domain multiple access (ToDMA), where a large number of devices share a token codebook and a modulation codebook for source and channel coding, respectively. Specifically, each transmitter first tokenizes its source signal and modulate each token to a codeword. At the receiver, compressed sensing is employed first to detect active tokens and the corresponding channel state information (CSI) from the superposed signals. Then, the source token sequences are reconstructed by clustering the token-associated CSI across multiple time slots. In case of token collisions, some active tokens cannot be assigned and some positions in the reconstructed token sequences are empty. We propose to use pre-trained MLLMs to leverage the context, predict masked tokens, and thus mitigate token collisions. Simulation results demonstrate the effectiveness of the proposed ToDMA framework for both text and image transmission tasks, achieving significantly lower latency compared to context-unaware orthogonal communication schemes, while also delivering superior distortion and perceptual quality compared to state-of-the-art context-unaware non-orthogonal communication methods.
Generative Video Semantic Communication via Multimodal Semantic Fusion with Large Model
Feb 19, 2025



Despite significant advancements in traditional syntactic communications based on Shannon's theory, these methods struggle to meet the requirements of 6G immersive communications, especially under challenging transmission conditions. With the development of generative artificial intelligence (GenAI), progress has been made in reconstructing videos using high-level semantic information. In this paper, we propose a scalable generative video semantic communication framework that extracts and transmits semantic information to achieve high-quality video reconstruction. Specifically, at the transmitter, description and other condition signals (e.g., first frame, sketches, etc.) are extracted from the source video, functioning as text and structural semantics, respectively. At the receiver, the diffusion-based GenAI large models are utilized to fuse the semantics of the multiple modalities for reconstructing the video. Simulation results demonstrate that, at an ultra-low channel bandwidth ratio (CBR), our scheme effectively captures semantic information to reconstruct videos aligned with human perception under different signal-to-noise ratios. Notably, the proposed ``First Frame+Desc." scheme consistently achieves CLIP score exceeding 0.92 at CBR = 0.0057 for SNR > 0 dB. This demonstrates its robust performance even under low SNR conditions.
Token Communications: A Unified Framework for Cross-modal Context-aware Semantic Communications
Feb 17, 2025



In this paper, we introduce token communications (TokCom), a unified framework to leverage cross-modal context information in generative semantic communications (GenSC). TokCom is a new paradigm, motivated by the recent success of generative foundation models and multimodal large language models (GFM/MLLMs), where the communication units are tokens, enabling efficient transformer-based token processing at the transmitter and receiver. In this paper, we introduce the potential opportunities and challenges of leveraging context in GenSC, explore how to integrate GFM/MLLMs-based token processing into semantic communication systems to leverage cross-modal context effectively, present the key principles for efficient TokCom at various layers in future wireless networks. We demonstrate the corresponding TokCom benefits in a GenSC setup for image, leveraging cross-modal context information, which increases the bandwidth efficiency by 70.8% with negligible loss of semantic/perceptual quality. Finally, the potential research directions are identified to facilitate adoption of TokCom in future wireless networks.
Token-Domain Multiple Access: Exploiting Semantic Orthogonality for Collision Mitigation
Feb 10, 2025



Token communications is an emerging generative semantic communication concept that reduces transmission rates by using context and transformer-based token processing, with tokens serving as universal semantic units. In this paper, we propose a semantic multiple access scheme in the token domain, referred to as ToDMA, where a large number of devices share a tokenizer and a modulation codebook for source and channel coding, respectively. Specifically, the source signal is tokenized into sequences, with each token modulated into a codeword. Codewords from multiple devices are transmitted simultaneously, resulting in overlap at the receiver. The receiver detects the transmitted tokens, assigns them to their respective sources, and mitigates token collisions by leveraging context and semantic orthogonality across the devices' messages. Simulations demonstrate that the proposed ToDMA framework outperforms context-unaware orthogonal and non-orthogonal communication methods in image transmission tasks, achieving lower latency and better image quality.
Diffusion-based Generative Multicasting with Intent-aware Semantic Decomposition
Nov 04, 2024



Generative diffusion models (GDMs) have recently shown great success in synthesizing multimedia signals with high perceptual quality enabling highly efficient semantic communications in future wireless networks. In this paper, we develop an intent-aware generative semantic multicasting framework utilizing pre-trained diffusion models. In the proposed framework, the transmitter decomposes the source signal to multiple semantic classes based on the multi-user intent, i.e. each user is assumed to be interested in details of only a subset of the semantic classes. The transmitter then sends to each user only its intended classes, and multicasts a highly compressed semantic map to all users over shared wireless resources that allows them to locally synthesize the other classes, i.e. non-intended classes, utilizing pre-trained diffusion models. The signal retrieved at each user is thereby partially reconstructed and partially synthesized utilizing the received semantic map. This improves utilization of the wireless resources, with better preserving privacy of the non-intended classes. We design a communication/computation-aware scheme for per-class adaptation of the communication parameters, such as the transmission power and compression rate to minimize the total latency of retrieving signals at multiple receivers, tailored to the prevailing channel conditions as well as the users reconstruction/synthesis distortion/perception requirements. The simulation results demonstrate significantly reduced per-user latency compared with non-generative and intent-unaware multicasting benchmarks while maintaining high perceptual quality of the signals retrieved at the users.
Private Collaborative Edge Inference via Over-the-Air Computation
Jul 30, 2024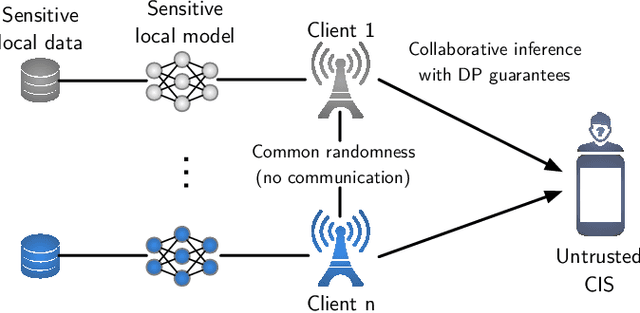

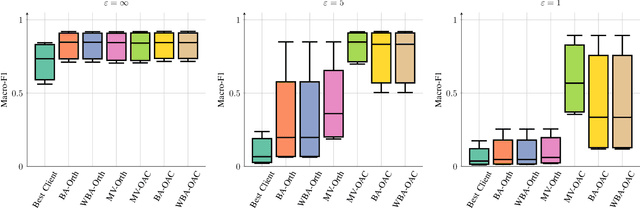
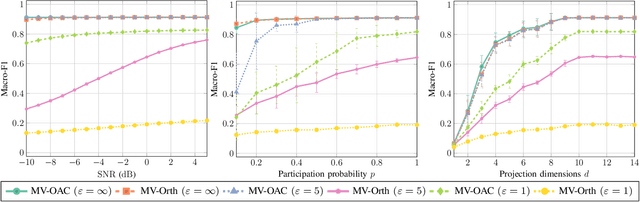
We consider collaborative inference at the wireless edge, where each client's model is trained independently on their local datasets. Clients are queried in parallel to make an accurate decision collaboratively. In addition to maximizing the inference accuracy, we also want to ensure the privacy of local models. To this end, we leverage the superposition property of the multiple access channel to implement bandwidth-efficient multi-user inference methods. Specifically, we propose different methods for ensemble and multi-view classification that exploit over-the-air computation. We show that these schemes perform better than their orthogonal counterparts with statistically significant differences while using fewer resources and providing privacy guarantees. We also provide experimental results verifying the benefits of the proposed over-the-air multi-user inference approach and perform an ablation study to demonstrate the effectiveness of our design choices. We share the source code of the framework publicly on Github to facilitate further research and reproducibility.
CSI-GPT: Integrating Generative Pre-Trained Transformer with Federated-Tuning to Acquire Downlink Massive MIMO Channels
Jun 05, 2024
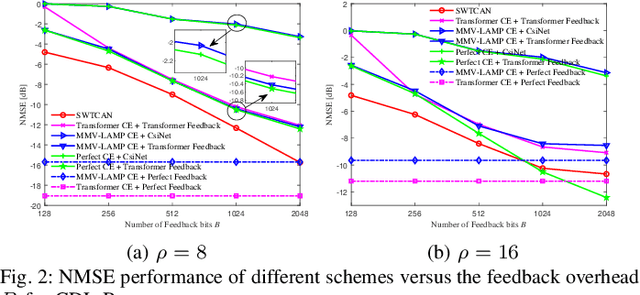

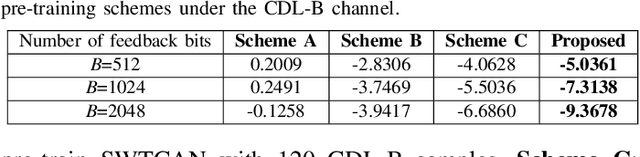
In massive multiple-input multiple-output (MIMO) systems, how to reliably acquire downlink channel state information (CSI) with low overhead is challenging. In this work, by integrating the generative pre-trained Transformer (GPT) with federated-tuning, we propose a CSI-GPT approach to realize efficient downlink CSI acquisition. Specifically, we first propose a Swin Transformer-based channel acquisition network (SWTCAN) to acquire downlink CSI, where pilot signals, downlink channel estimation, and uplink CSI feedback are jointly designed. Furthermore, to solve the problem of insufficient training data, we propose a variational auto-encoder-based channel sample generator (VAE-CSG), which can generate sufficient CSI samples based on a limited number of high-quality CSI data obtained from the current cell. The CSI dataset generated from VAE-CSG will be used for pre-training SWTCAN. To fine-tune the pre-trained SWTCAN for improved performance, we propose an online federated-tuning method, where only a small amount of SWTCAN parameters are unfrozen and updated using over-the-air computation, avoiding the high communication overhead caused by aggregating the complete CSI samples from user equipment (UEs) to the BS for centralized fine-tuning. Simulation results verify the advantages of the proposed SWTCAN and the communication efficiency of the proposed federated-tuning method.
Massive Digital Over-the-Air Computation for Communication-Efficient Federated Edge Learning
May 24, 2024



Over-the-air computation (AirComp) is a promising technology converging communication and computation over wireless networks, which can be particularly effective in model training, inference, and more emerging edge intelligence applications. AirComp relies on uncoded transmission of individual signals, which are added naturally over the multiple access channel thanks to the superposition property of the wireless medium. Despite significantly improved communication efficiency, how to accommodate AirComp in the existing and future digital communication networks, that are based on discrete modulation schemes, remains a challenge. This paper proposes a massive digital AirComp (MD-AirComp) scheme, that leverages an unsourced massive access protocol, to enhance compatibility with both current and next-generation wireless networks. MD-AirComp utilizes vector quantization to reduce the uplink communication overhead, and employs shared quantization and modulation codebooks. At the receiver, we propose a near-optimal approximate message passing-based algorithm to compute the model aggregation results from the superposed sequences, which relies on estimating the number of devices transmitting each code sequence, rather than trying to decode the messages of individual transmitters. We apply MD-AirComp to the federated edge learning (FEEL), and show that it significantly accelerates FEEL convergence compared to state-of-the-art while using the same amount of communication resources. To support further research and ensure reproducibility, we have made our code available at https://github.com/liqiao19/MD-AirComp.