 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Invariant Global Pooling
May 30, 2023

Much work has been devoted to devising architectures that build group-equivariant representations, while invariance is often induced using simple global pooling mechanisms. Little work has been done on creating expressive layers that are invariant to given symmetries, despite the success of permutation invariant pooling in various molecular tasks. In this work, we present Group Invariant Global Pooling (GIGP), an invariant pooling layer that is provably sufficiently expressive to represent a large class of invariant functions. We validate GIGP on rotated MNIST and QM9, showing improvements for the latter while attaining identical results for the former. By making the pooling process group orbit-aware, this invariant aggregation method leads to improved performance, while performing well-principled group aggregation.
Finding the Needle in a Haystack: Unsupervised Rationale Extraction from Long Text Classifiers
Mar 14, 2023Long-sequence transformers are designed to improve the representation of longer texts by language models and their performance on downstream document-level tasks. However, not much is understood about the quality of token-level predictions in long-form models. We investigate the performance of such architectures in the context of document classification with unsupervised rationale extraction. We find standard soft attention methods to perform significantly worse when combined with the Longformer language model. We propose a compositional soft attention architecture that applies RoBERTa sentence-wise to extract plausible rationales at the token-level. We find this method to significantly outperform Longformer-driven baselines on sentiment classification datasets, while also exhibiting significantly lower runtimes.
Turning transformer attention weights into zero-shot sequence labelers
Mar 26, 2021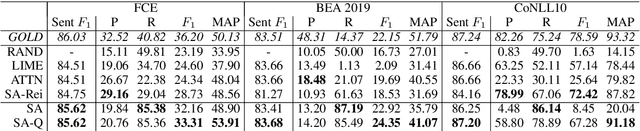
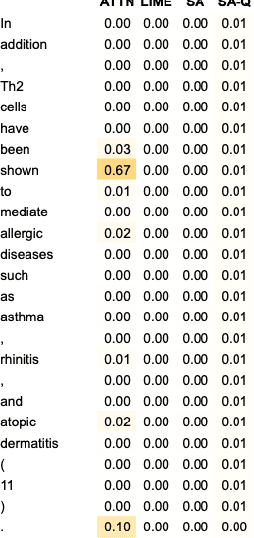
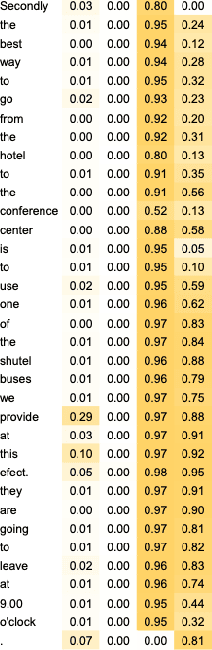
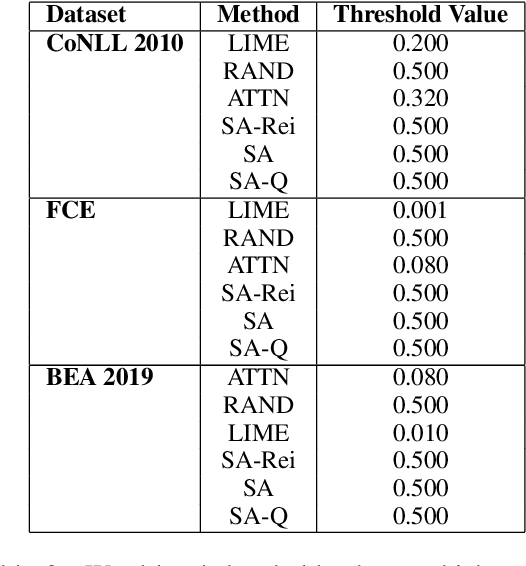
We demonstrate how transformer-based models can be redesigned in order to capture inductive biases across tasks on different granularities and perform inference in a zero-shot manner. Specifically, we show how sentence-level transformers can be modified into effective sequence labelers at the token level without any direct supervision. We compare against a range of diverse and previously proposed methods for generating token-level labels, and present a simple yet effective modified attention layer that significantly advances the current state of the art.